When a patient describes a complex set of symptoms to an AI triage system, the system needs to navigate a structured decision tree. This ensures we ask the right questions in the right order while keeping the conversation natural. For a human clinician, this is second nature. For a large language model (LLM) this challenge has always been unreliable using standard prompting techniques.
Standard approaches to LLM-powered clinical workflows embed the full decision tree directly into the prompt. This asks the model to simultaneously perform all of the following tasks at once:
- Understand the tree structure
- Manage the conversational state
- Evaluate transition conditions
- Generate natural language responses
As a result, systems lose track of where they are, skip critical questions, or hallucinate transitions that do not exist. All of this happens while racking up high inference costs from processing enormous context at every turn.
Today, we are presenting Arbor, a framework that decomposes that decision tree navigation into smaller specialized, node-level tasks.
Rather than forcing an LLM to process an entire decision structure at once, Arbor provides a framework for consistently improved accuracy and speed at scale by:
- Dynamically retrieving only the context relevant to each decision point
- Separating logical evaluation from response generation
- Using graph-based orchestration to maintain strict procedural adherence
Arbor has been rigorously evaluated across a diverse set of foundation models using real-world clinical triage conversations. The results are impressive, with Arbor achieving over 29 percentage points higher navigation accuracy, 57% lower latency, and 14.4× lower cost compared to single-prompt baselines.
Smarter AI Care
Arbor outperforms standard approaches to LLM prompting
29%
Higher navigation accuracy
57%
Lower latency
14.4x
Lower cost
Why single-prompt approaches fail in structured workflows
The most common approach to LLM-powered decision tree navigation is to include the entire tree into the system prompt and instruct the model to navigate it autonomously. While conceptually simple, this strategy faces several well-documented challenges.
- Context and attention degradation. As prompt length increases, models exhibit instruction-following degradation and the well-known "lost-in-the-middle" effect, where relevant information buried in long contexts is poorly attended. Large clinical decision trees can exceed context window limits entirely. In our evaluation, the fully serialized tree occupied approximately 120,000 tokens.
- Violation of separation of concerns. A single prompt asks the model to handle multiple heterogeneous tasks simultaneously: parsing tree structure, tracking conversational state, evaluating transition conditions, and generating natural language responses. This conflicts with well-documented limitations of LLMs in multi-step reasoning, leading to degraded performance as task complexity increases.
- Opaque failures. When the model selects an incorrect transition, it is difficult to determine whether the error stems from misunderstanding the tree, mis-evaluating conditions, or losing track of conversational context. Debugging becomes guesswork.
Taken together, these limitations highlight a fundamental weakness of autonomous, single-prompt navigation in structured workflows.
Arbor takes a different approach by offering an orchestrated architecture that constrains the model’s reasoning to local decisions.
How Arbor works
Arbor’s architecture follows a decomposition principle and is organized into two core components: a tree standardization pipeline and a graph-based conversational agent.
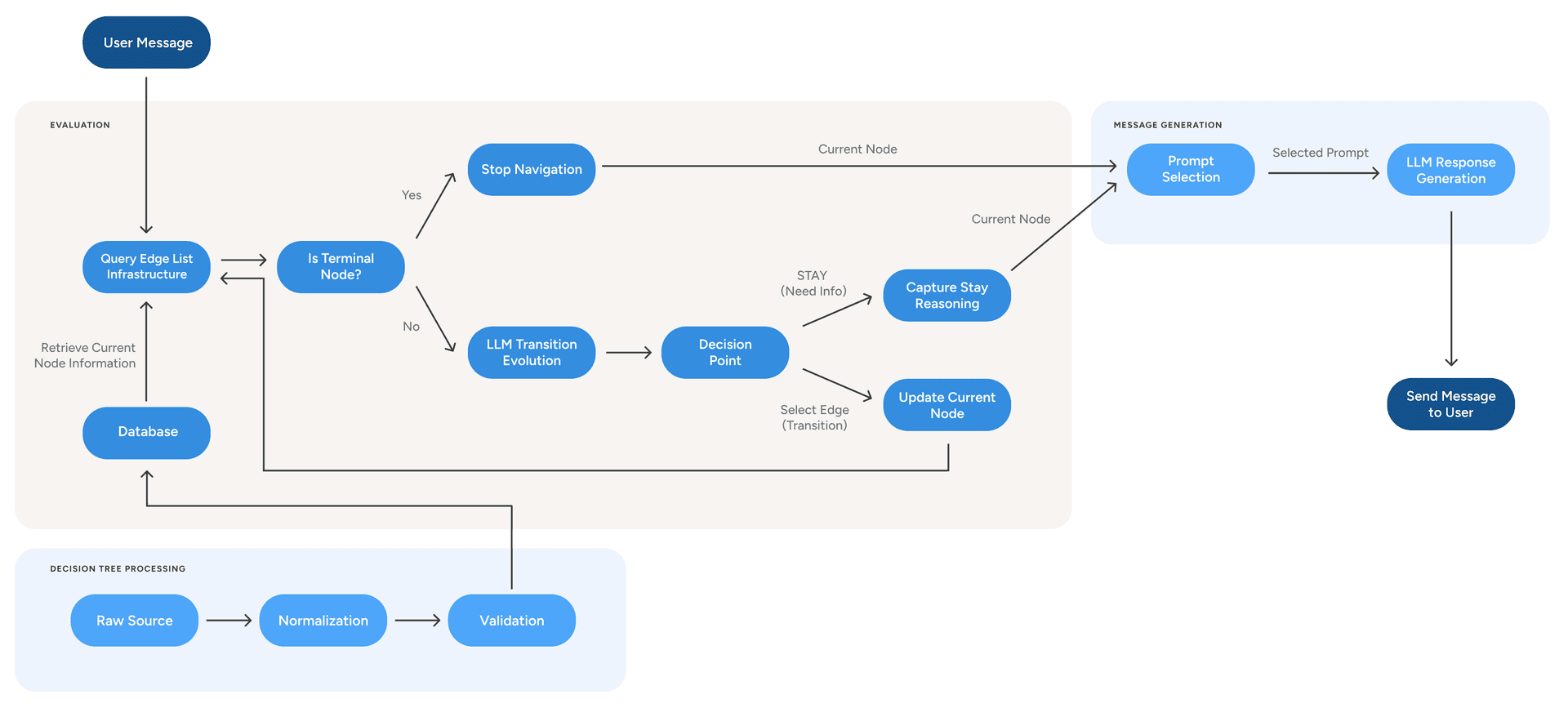
Figure 1. Arbor’s architecture normalizes a decision tree into an edge list, evaluates transitions iteratively, and then generates the user response.
Processing the decision tree
The framework begins by transforming any decision tree, regardless of its source format, into a standardized edge-list representation, where each edge corresponds to a single possible transition.
This edge list is ingested into a scalable, low-latency retrieval system. Before indexing, the pipeline performs structural validation by detecting orphan nodes, verifying reference integrity, and identifying inescapable loops using strongly connected component analysis.
As a result, this design decouples the agent architecture from any specific decision tree structure. Clinical teams can update branching logic, refine node content, or introduce new decision paths without requiring changes to the agent code.
The two-step agent loop
At runtime, each user interaction executes a loop composed of two independent steps:
Step 1: Dynamic retrieval and transition evaluation. The agent queries the storage system using the current node identifier, retrieving only the outgoing edges from that node. These edges, together with the conversation history and any external context, are passed to an LLM configured specifically for transition evaluation. The model evaluates the user’s response against the candidate transitions and selects the most appropriate one, or decides to remain at the current node if more information is needed. This evaluation is iterative: if the agent transitions to a new node, it immediately repeats the process, allowing multiple nodes to be traversed in a single turn.
Step 2: Message generation. A second, independent LLM call generates the user-facing response. This step receives the current node’s content, the transition reasoning from Step 1, and the conversation history. It focuses exclusively on producing natural, contextually appropriate responses.
Arbor's results: improvements in accuracy, latency, and cost
We evaluated Arbor against a single-prompt baseline across nine foundation models, including both proprietary and open-weight options. The evaluation used 20 real-world triage conversations comprising 174 decision points, with a decision tree containing 449 nodes and 980 edges.
Navigation accuracy
We first assessed the reliability of the system by measuring how often it correctly identified the next step in a clinical flow.
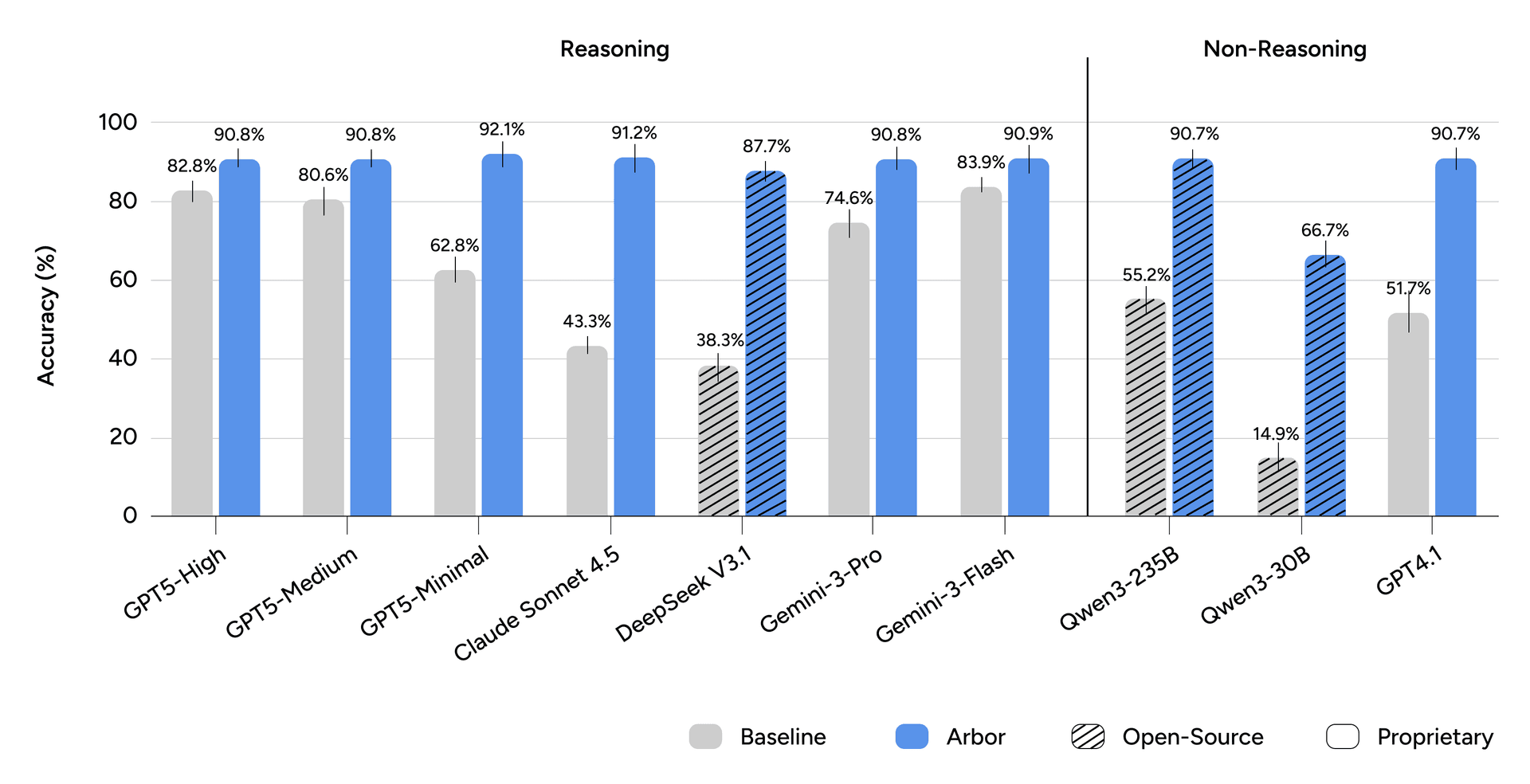
Figure 2. Turn accuracy. Bars show mean turn accuracy over five runs; error bars indicate the standard deviation.
Under the single-prompt baseline, navigation accuracy varies widely across models. With Arbor, accuracy consistently converges near 90% for all evaluated models. Averaged across all models, Arbor improves navigation accuracy by 29 percentage points while substantially reducing variance.
Single-prompt navigation performance is fundamentally capability-bound, whereas Arbor makes accuracy primarily a function of system architecture.
Latency and cost
Efficiency matters in real-world deployments, so we measured per-turn latency and cost alongside accuracy.
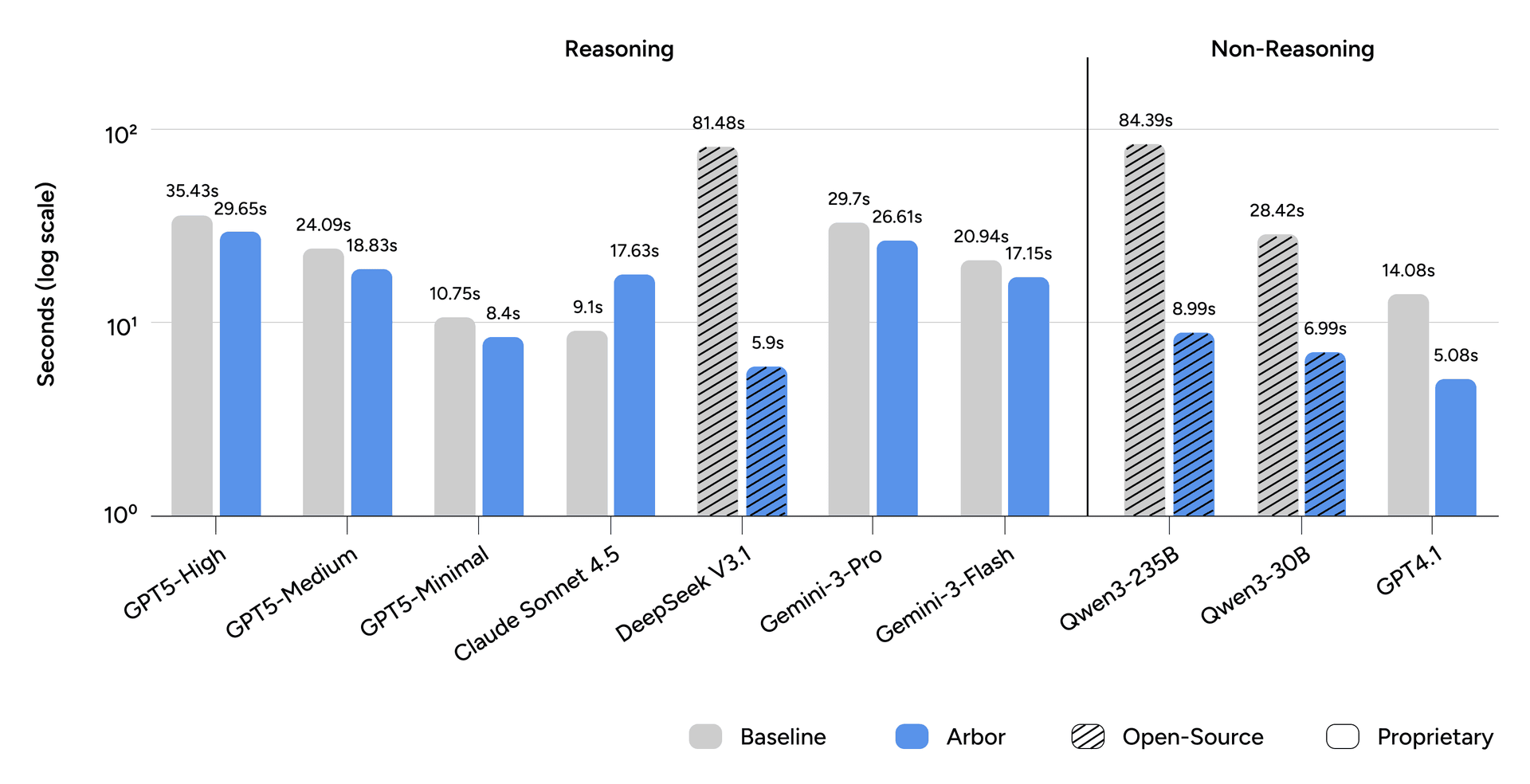
Figure 3: Cost per Turn. Bars show the average cost per conversational turn in US dollars ($). The y-axis is on a log scale.
The single-prompt approach requires re-ingesting the full decision tree at every conversational turn, causing cost to scale directly with tree size. Arbor restricts the context window to the active decision node, achieving an average 14.4× reduction in per-turn cost.
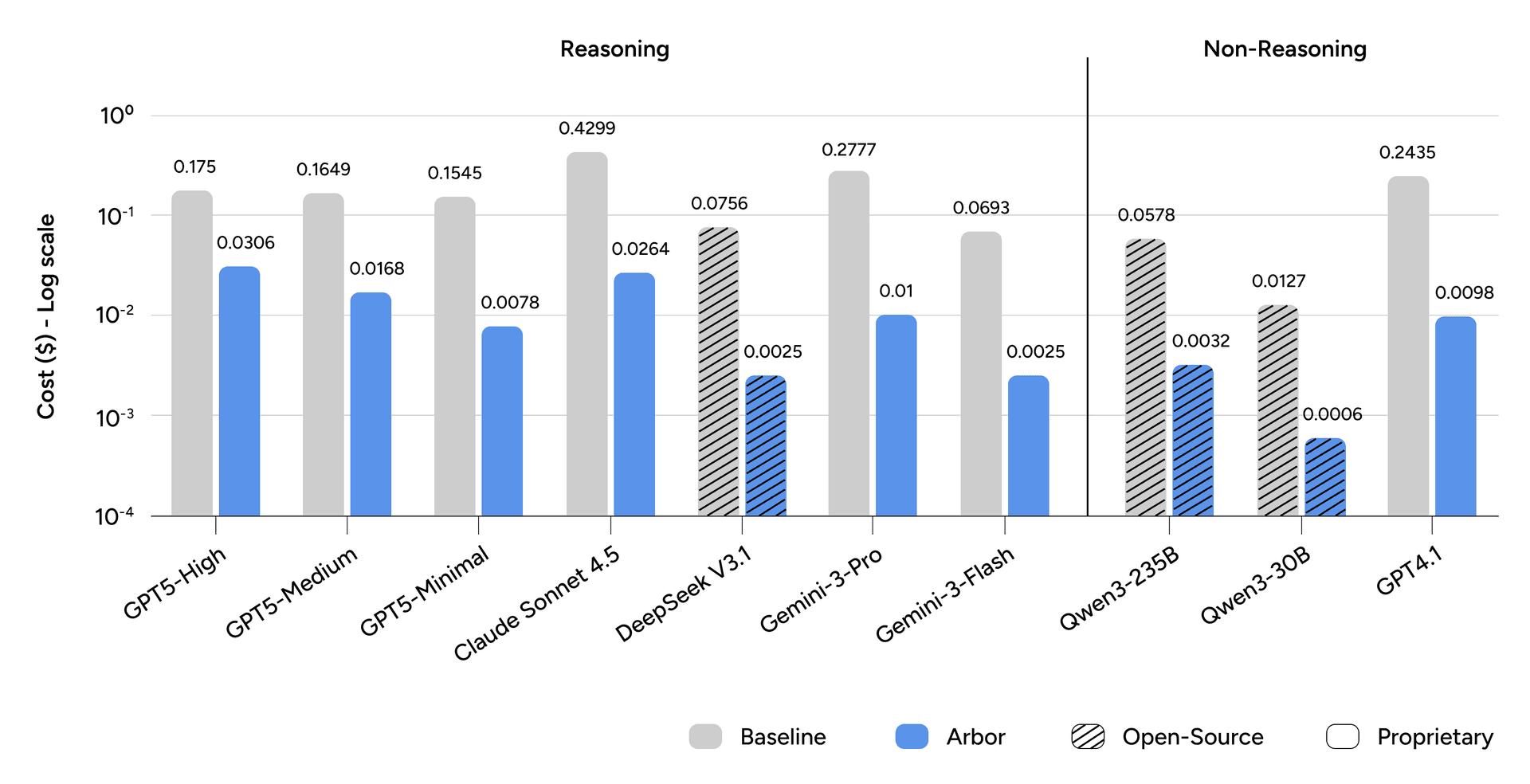
Figure 4: Latency per Turn. Bars show mean response latency, in seconds, over five runs. The y-axis is on a log scale.
Latency also improves substantially, with mean per-turn latency decreasing from 33.8 seconds to 14.5 seconds, a 57.1% reduction. While multi-step architectures introduce predictable overhead, the single-prompt approach can incur severe penalties from processing very large context windows, particularly for open-source models.
Message quality is preserved
A critical question is whether this structural decomposition compromises conversational naturalness. To assess this, three licensed physical therapists independently evaluated 150 messages from both approaches on turns where both selected the correct node.
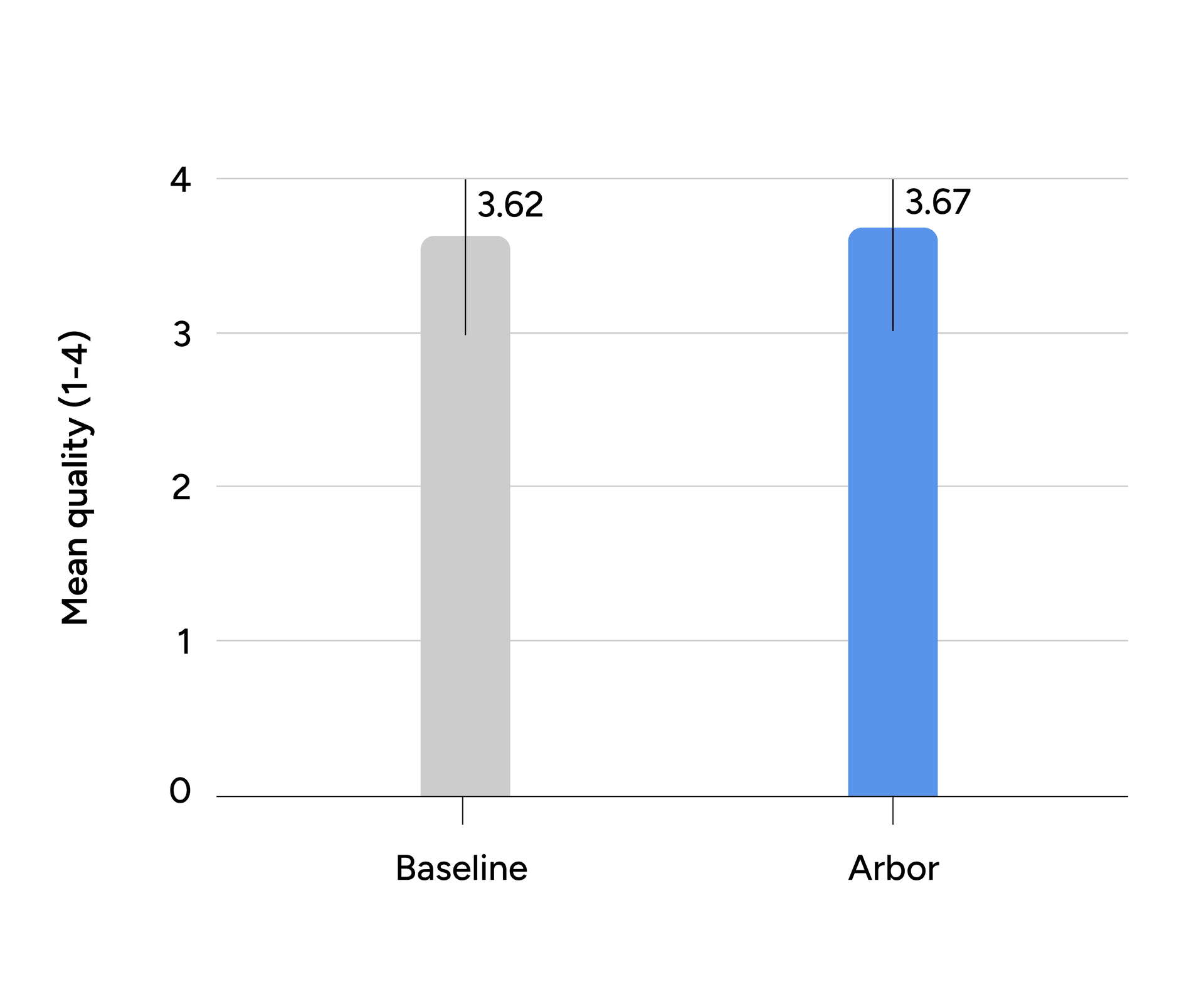
Figure 5: Average Quality Score. Bars show the mean quality rating of accepted messages on a scale of 1 to 4; error bars indicate the standard deviation.
The framework achieved a 97.3% clinical acceptance rate and an average quality score of 3.67 out of 4, closely matching the single-prompt baseline score of 3.62. The difference is not statistically significant. These results indicate that separating evaluation from generation does not sacrifice conversational quality.
Limitations and future directions
Arbor represents meaningful progress, but important limitations remain.
Forward-only traversal. The current framework assumes forward-only navigation through the decision tree. While some correction can be encoded at the tree design level, native support for explicit backtracking would better handle contradictory user input or revisions to earlier responses.
State drift over long conversations. Over extended interactions, accumulated ambiguity or misinterpretation may cause the agent’s internal state to diverge from the user’s intent. Future extensions could allow the agent to periodically reassess state consistency against the full conversation context.
Latency for real-time applications. While Arbor often outperforms single-prompt approaches in latency, applications with strict real-time constraints, such as voice interactions, may benefit from further optimization. Possible optimizations include reflective listening strategies or model distillation for high-confidence decision points.
Toward reliable conversational AI in high-stakes domains
Building reliable AI-based systems for clinical workflows requires moving beyond standard prompt engineering toward system-level architectural design. Arbor demonstrates that decomposing complex decision processes into specialized tasks, constraining reasoning to local decisions within an orchestrated framework, yields more stable and effective behavior than relying on raw model capability alone.
While motivated by clinical triage, this design principle generalizes to domains where conversational agents must adhere to predefined procedures or protocols. By reconciling the flexibility of modern language models with the rigor of structured decision logic, Arbor provides a scalable foundation for deploying reliable conversational AI in high-stakes environments.
About the author

Sword Health Innovation Team
Exploring the breakthroughs behind AI Care.