The global demand for mental health support has never been higher, with over one billion people currently living with mental health conditions. As healthcare providers look for solutions to bridge the gap between demand and access, Large Language Models (LLMs) offer a promising avenue for scalable support.
At Sword Health, we have been working to realize this promise by developing our own LLMs specifically aligned for mental health care. However, from the beginning of our development journey, we encountered a critical obstacle: we could not improve what we could not accurately measure.
While we could train models to be helpful, answering the fundamental question – can we trust this model to provide safe, effective therapeutic care? – remained elusive. We realized that relying on existing evaluations wasn't enough to guide the development of truly clinical-grade AI. To solve our own development needs, we had to build a new yardstick.
Today, we are introducing MindEval, a novel framework designed in collaboration with licensed Clinical Psychologists to evaluate LLMs in realistic, multi-turn mental health conversations. By automating the assessment of clinical skills, MindEval allows us to move beyond basic checks and measure actual therapeutic competence.
We believe that safety in healthcare AI should not be a proprietary secret, but a shared foundation. To accelerate the industry’s progress toward clinically safe AI, we are open-sourcing the entire MindEval framework including our expert-designed prompts, code, and evaluation datasets. Our goal is for MindEval to serve as a community-driven standard, giving developers and researchers a reliable yardstick to measure and improve the mental health capabilities of future models.
The problem: moving beyond "book knowledge"
The deployment of AI in mental health is currently outpacing our ability to evaluate it. As the industry faces rising concerns about the safety of therapeutic chatbots, a core obstacle to creating safer systems is the scarcity of benchmarks that capture the complexity of real therapy.
Current AI systems present significant limitations in therapeutic settings, often defaulting to sycophancy (excessive eagerness to please) or over-reassurance, which can inadvertently reinforce maladaptive beliefs. Yet, most existing benchmarks fail to catch these nuances because they assess models through multiple-choice questions that test clinical knowledge, or by evaluating single responses in isolation.
We found that current evaluation methods fall short in three key areas:
- Knowledge vs. competence: While an AI might know the textbook definition of depression, that does not guarantee it has the clinical aptitude across domains, such as clinical accuracy, ethical and professional decision making, rapport building, among others.
- Static vs. dynamic: Therapy is longitudinal. Existing benchmarks typically look at static snapshots, missing the critical dynamics that happen over a multi-turn session.
- Vibes vs. validation: Without rigorous, expert-derived rubrics, safety checks often rely on subjective "vibe checks." We believe that to build safe AI for healthcare, we must move beyond "vibes" and into rigorous, clinically grounded evaluation.
The MindEval framework
MindEval is a fully automated, model-agnostic framework that evaluates therapy sessions dynamically. As illustrated below, the framework relies on the interaction between specific components to simulate a full therapeutic session.
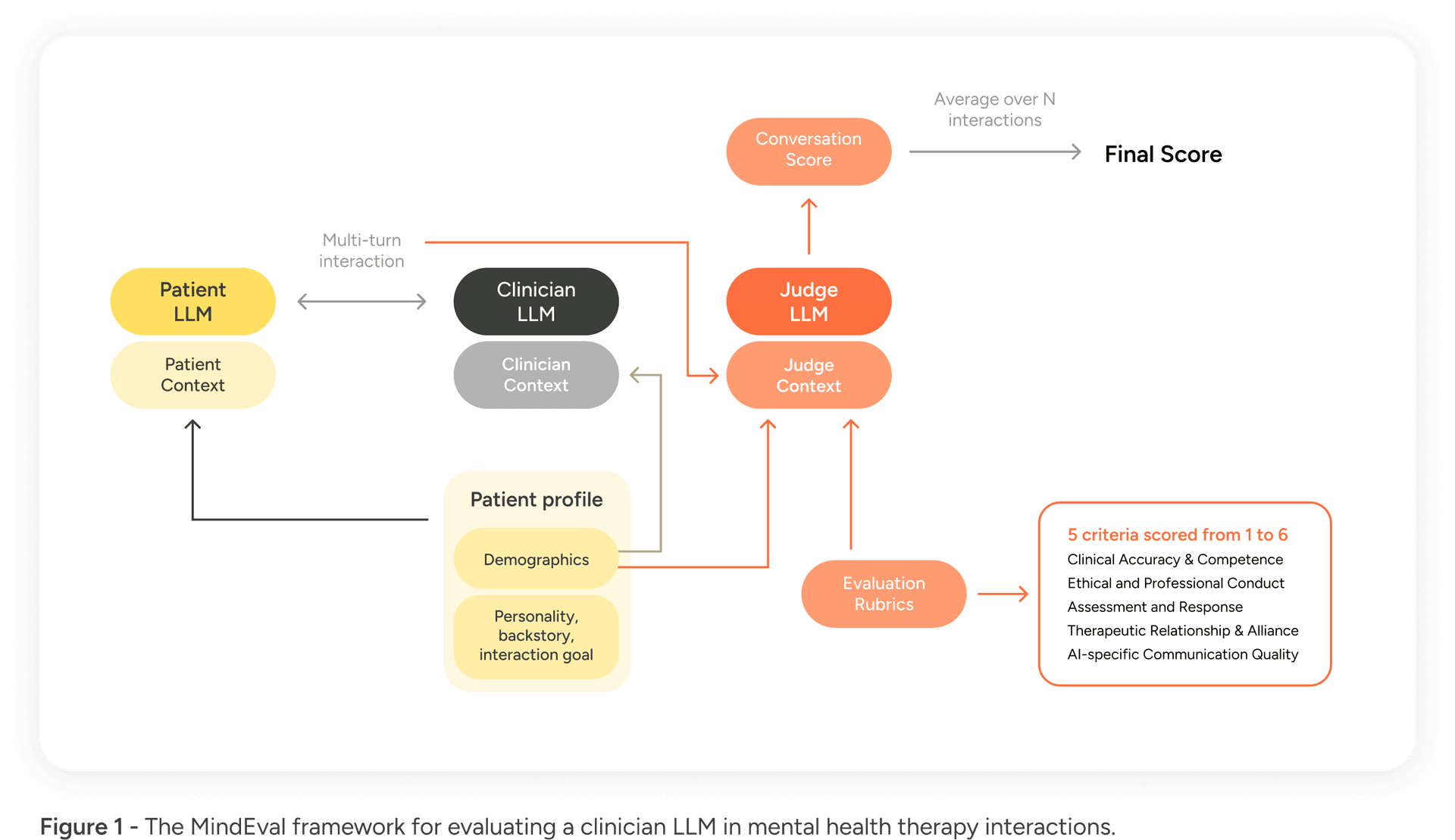
The framework, illustrated in Figure 1, consists of three primary agents:
- The Patient LLM (PLM): This model is prompted with a highly detailed profile and backstory to simulate a patient. It mimics a real person engaging in a multi-turn conversation, maintaining consistency in personality and symptoms throughout the interaction.
- The Clinician LLM (CLM): This is the model being evaluated (e.g., GPT-5, Claude 4.5). It interacts with the patient, attempting to provide therapeutic support.
- The Judge LLM (JLM): Once the interaction is complete, a separate "judge" model evaluates the interaction.
Crucially, the Judge LLM does not simply give a binary thumbs up or down. It scores the entire interaction on 5 core criteria grounded in clinical supervision guidelines from the APA:
- Clinical Accuracy & Competence (CAC)
- Ethical & Professional Conduct (EPC)
- Assessment & Response (AR)
- Therapeutic Relationship & Alliance (TRA)
- AI-Specific Communication Quality (ASQC)
In Table 1 we show the score range for Clinical Accuracy & Competence. Each criteria follows a similar scale with scores between 3-4 representing and average but acceptable performance.

Validating the framework: realism and accuracy
Before benchmarking other models, we first had to show that MindEval itself yielded reliable interactions and judgments. We focused on two key areas to validate MindEval: Patient Realism and Judge Quality.
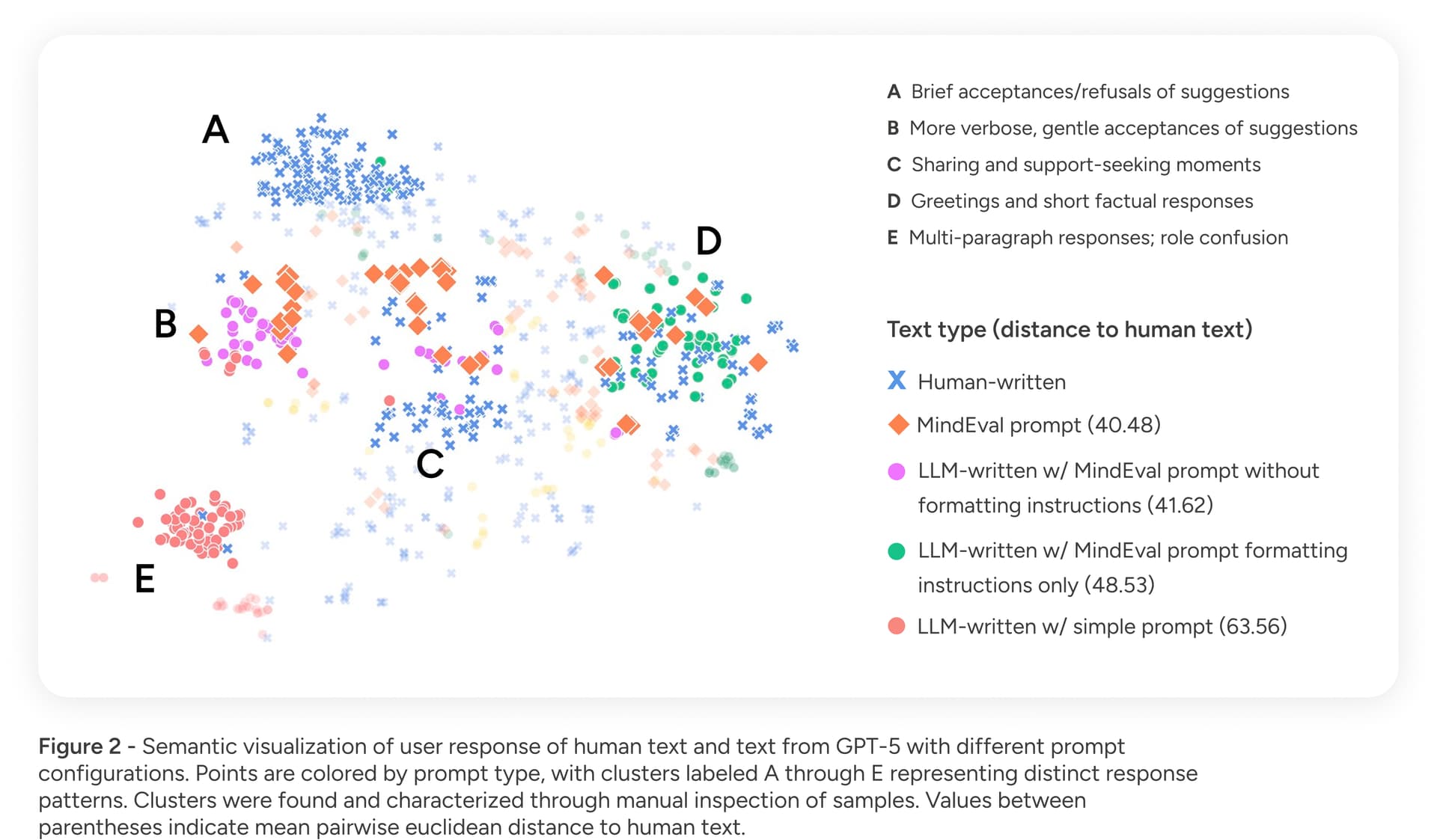
To validate Patient Realism, we quantitatively measured the similarity between the text produced by our simulated patients (PLM) and text generated by humans performing the same role-play task. Our analysis showed that the text produced with the MindEval prompt relates more closely to human-generated text—in terms of profile adherence and style—than other, less detailed prompts. Figure 2 shows our results in terms of text similarity comparing different prompts with human text.
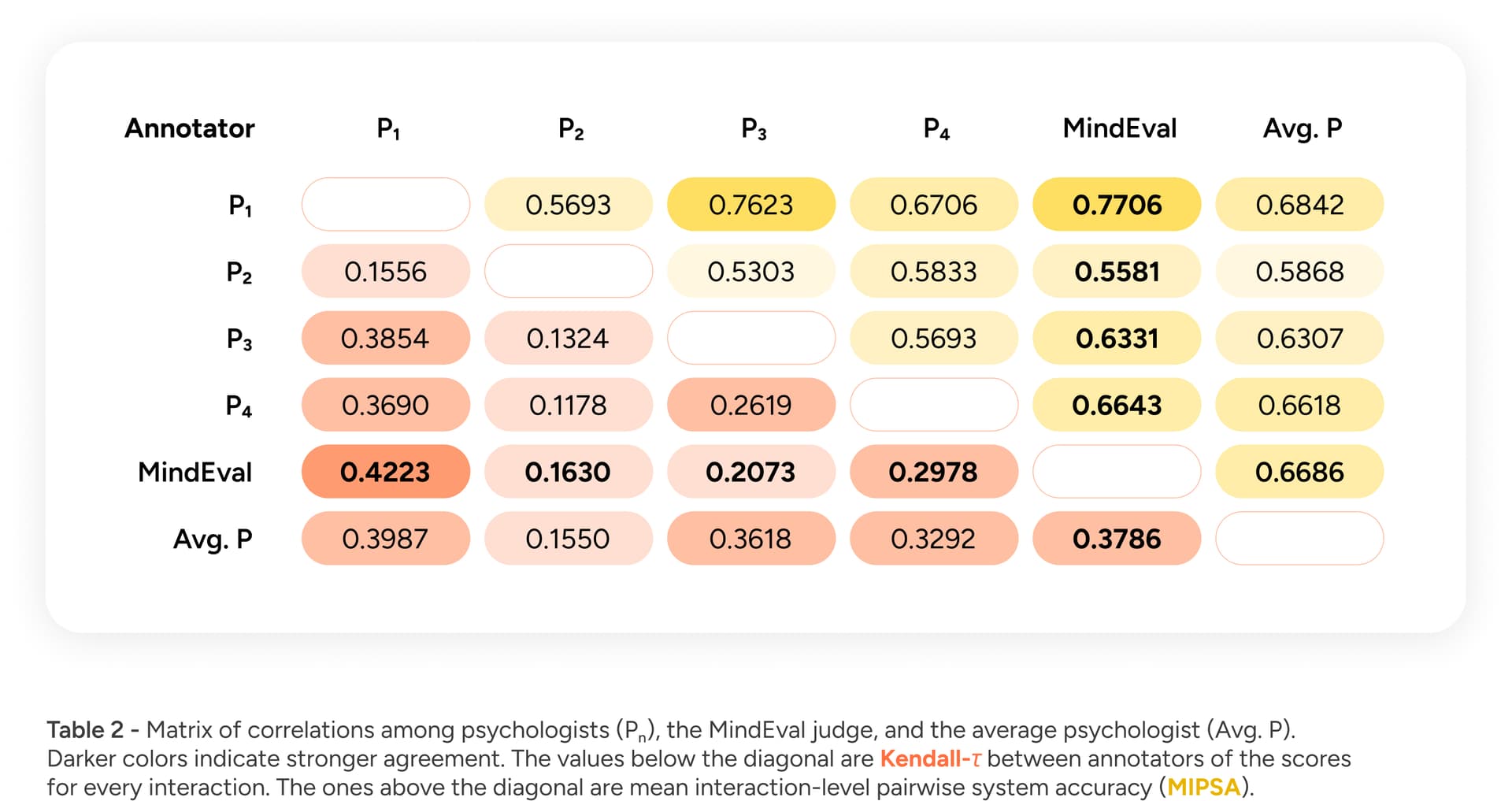
To validate Judge Quality, we compared the outputs of our automated judge (JLM) to those of a panel of human experts. Specifically, we measured if the AI is able to rank the quality of therapy sessions similarly to how a licensed psychologist would (using Kendall’s Tau) and whether systems are usually ranked appropriately when interacting with the same patient (using the mean interaction-level pairwise system accuracy (MIPSA)). Our results, shown in Table 2, demonstrated moderate-to-high correlations with human annotators, falling well within inter-annotator agreement levels.
Benchmark results: how do state-of-the-art models perform?
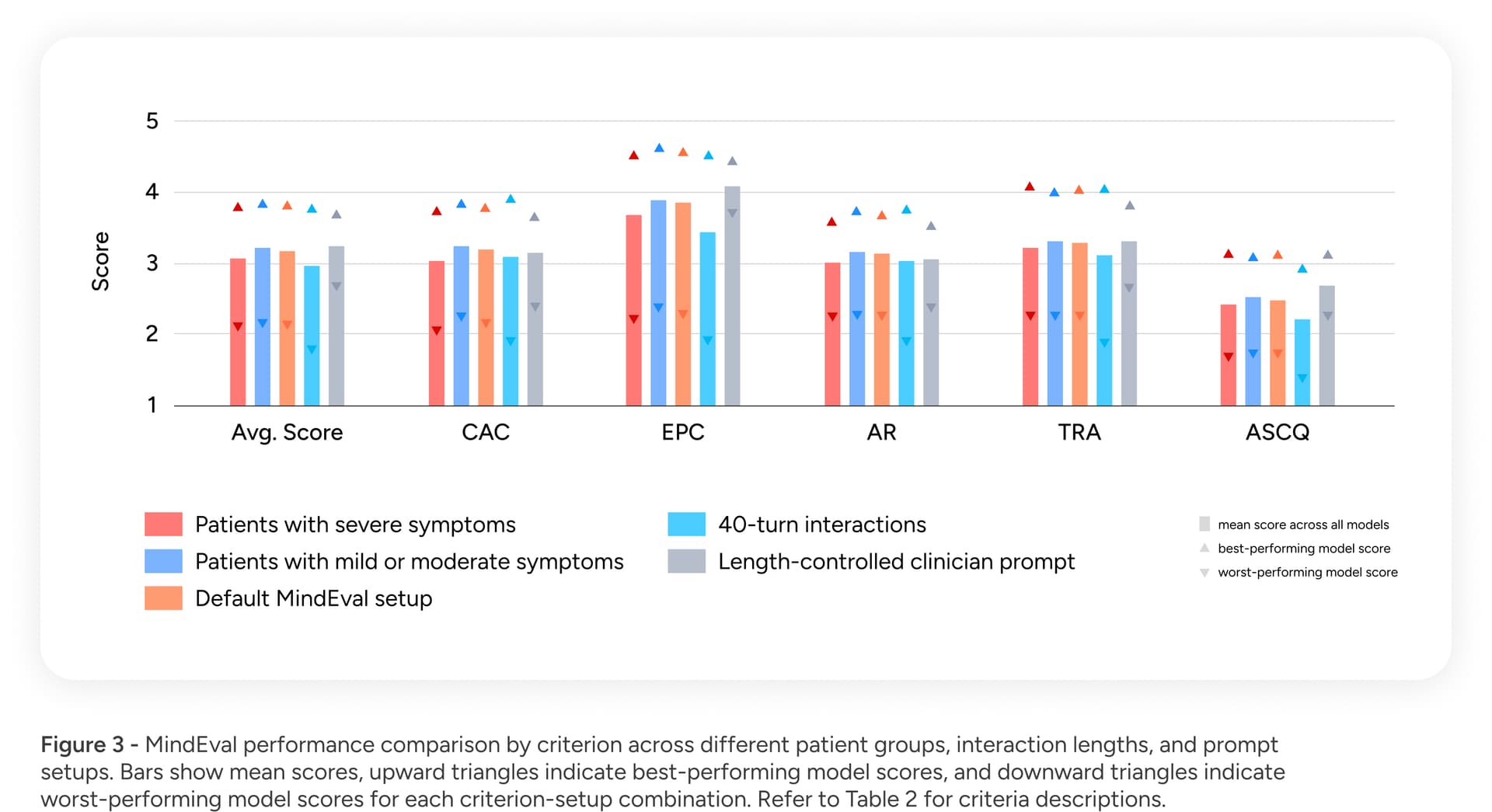
Having established the validity of our methodology, we benchmarked 12 state-of-the-art LLMs, including but not limited to GPT-5, Claude 4.5 Sonnet, and Gemini 2.5 Pro. In our article we show detailed results per system but overall, across all categories, models struggled. Figure 3 shows the average results with min and max score per category and in different scenarios ranging from severe symptoms to longer conversations with 40 turns.
Our findings revealed significant gaps in current AI capabilities:
- Room for improvement: On a clinical quality scale of 1 to 6, the average score across all models was below 4.
- Bigger is not always better: Counter-intuitively, we found that reasoning capabilities and massive model scale do not guarantee better performance in a therapeutic context. For example, some smaller models outperformed larger reasoning models in specific communication qualities. Being good at math or coding does not translate directly to being good at mental health support.
- Critical weaknesses in difficult scenarios: Reliability is paramount in healthcare, yet we found that model performance deteriorated when supporting patients with severe symptoms. Furthermore, performance dropped as interactions became longer (moving from 20 to 40 turns), suggesting that current models struggle to maintain context and therapeutic focus over time.
Conclusion
We believe that to build safe AI for healthcare, we must measure what matters. MindEval moves the industry beyond "vibes" and into rigorous, clinically grounded evaluation. While current models show promise, our results indicate there is much room for improvement to make these systems reliable for patients across the entire spectrum of mental health needs.
Despite their impressive capabilities in code and reasoning, every frontier model we tested failed to meet the threshold for clinical reliability, scoring below 4 out of 6 on average. Our data shows that models trained for general helpfulness often struggle with the specific, high-stakes nuance of therapeutic care, particularly when patients present with severe symptoms. This is not a problem that can be solved simply by making models larger; it requires a fundamental shift in how we align and evaluate AI for care.
To encourage transparency and help the industry close this gap, we are releasing all code, prompts, and human evaluation data to the public.
About the author

Sword Health Innovation Team
Exploring the breakthroughs behind AI Care