
Introduction
Despite the substantial technological advances of recent decades, the way care is delivered has evolved far more slowly. Care delivery continues to depend primarily on one factor: human availability. Effective care requires continuous, individualized attention, which makes it inherently difficult to standardize or scale. Phoenix was created to bridge this gap.
Phoenix is Sword Health's AI Care Specialist, combining AI with clinical expertise to support members throughout their treatment journey. In session, Phoenix talks with members as they move, adapts to how they are doing, and brings therapist-level guidance into every interaction. Between sessions, Phoenix distills what was captured in real time into actionable insights that clinicians can use to guide care at scale without losing quality or human connection.
This article focuses on Phoenix’s in-session real-time voice-based communication capabilities. In this setting, Phoenix is not a general-purpose assistant handling casual inquiries. It must remain contextually aware, motivational, and fully aligned with therapeutic guidelines established by clinicians. We walk through how we approached these challenges, the architecture and decisions behind it, the safeguards that ensure reliability, and what this means for scaling Sword’s AI-driven healthcare to billions of people.
Phoenix in action: the member experience
From the very beginning of a session, Phoenix sets the tone. It greets the member, sets expectations for the activity ahead, and follows up on any pending issues from previous sessions. This opening moment serves a real purpose: it establishes continuity, checks in on how the member is feeling, and even allows for light adjustments to the plan. For example, it can dial back intensity if the member mentions soreness, all within pre-approved clinical guidelines.
Once the session is underway, Phoenix remains present. It explains each exercise, answers questions (members can say Hey Phoenix to start a conversation), responds to voice commands, and provides exercise-specific tips to help the member get the most out of their session. As the session unfolds, Phoenix communicates the results back in real time, reinforcing the correct form, suggesting small adjustments, and keeping engagement high.

Figure 1: Phoenix guiding a member through an exercise - real-time motion tracking and conversational feedback help ensure correct form and keep the session engaging.
At the close of the session, Phoenix circles back to the member’s experience: How did it feel? Was anything painful or too easy? The clinician overseeing the program receives this feedback alongside session performance data, making it easier to adjust and optimize the next prescription. Phoenix can also draw on context from the clinician’s latest inputs (from program adjustments to shared advice), forming a two-way loop between Phoenix and the Clinical Specialist, one we’ll return to later.
Building the foundation: voice-first care
Seeing Phoenix guide a member through a session naturally raises the question: how does it actually work under the hood? Here’s what the architecture looks like (Figure 2):
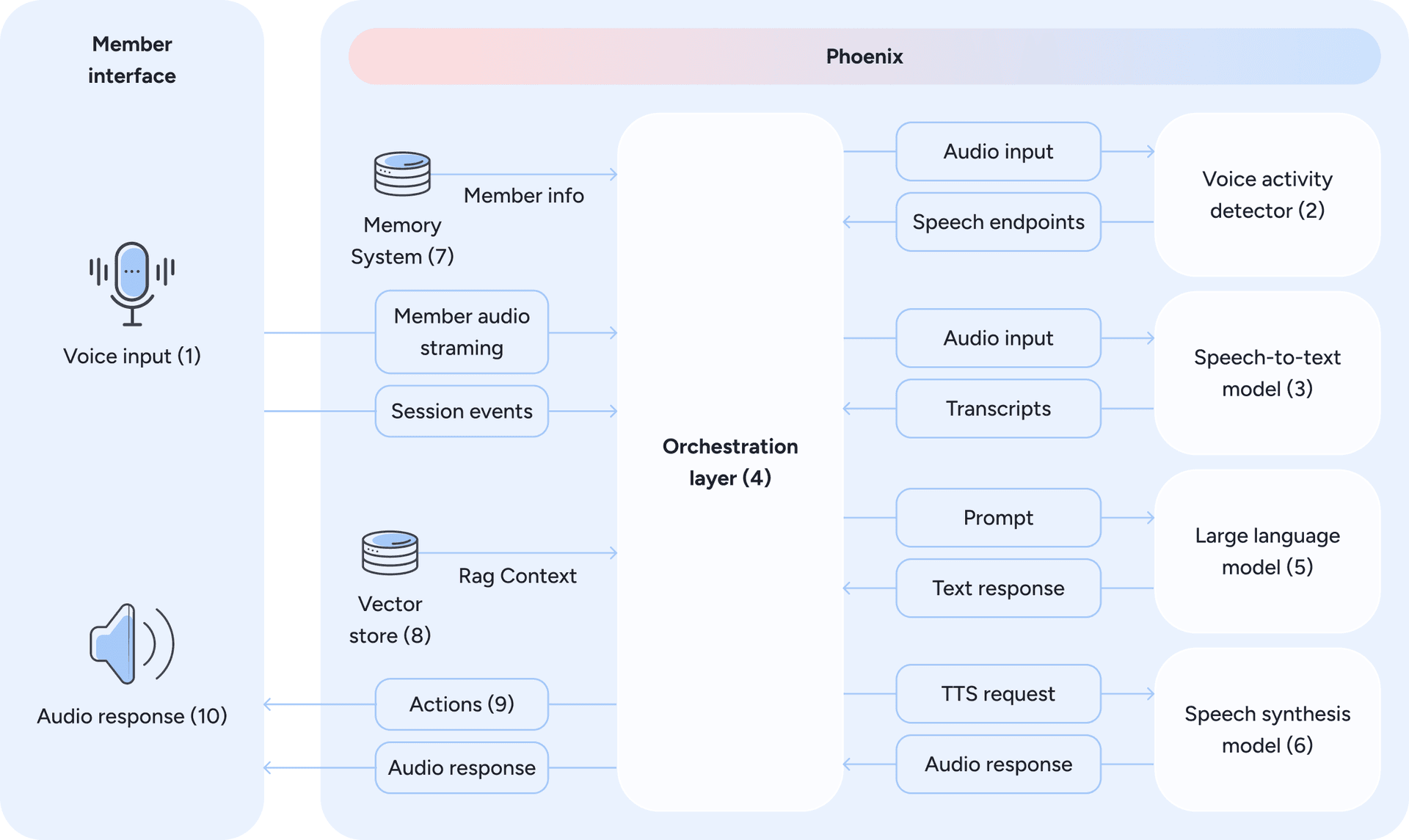
Figure 2: Phoenix’s voice-first architecture - from member speech to contextualized, real-time voice responses, mediated by an orchestration layer.
At its core, the system follows a modular pipeline: speech-to-text (STT) (2 and 3) → large language model (LLM) (5) → text-to-speech (TTS) (6). The member’s voice is transcribed in real time, the LLM produces a response, and the reply is voiced back instantly. What makes this challenging is the need for low latency as even small delays can break the illusion of a natural exchange.
Phoenix achieves this through the following components and strategies:
- A voice activity and turn-taking model continuously analyzes incoming audio to estimate the probability that the member is actively speaking at each moment. From this signal, the system derives a continuous potential end-of-speech estimate based on acoustic features such as pauses, energy decay, and prosody. This probabilistic formulation enables Phoenix to anticipate turn boundaries and engage in natural conversational turn-taking. To minimize latency and avoid unnatural waiting periods, the orchestration layer triggers LLM response generation speculatively when the potential end-of-speech signal crosses a predefined threshold and barge-in risk is low. Response generation may begin before speech is definitively finished and can be cancelled or paused if the member resumes speaking. This approach reduces perceived latency while preserving natural conversational flow. The dynamics of this speculative approach are illustrated in Figure 3.
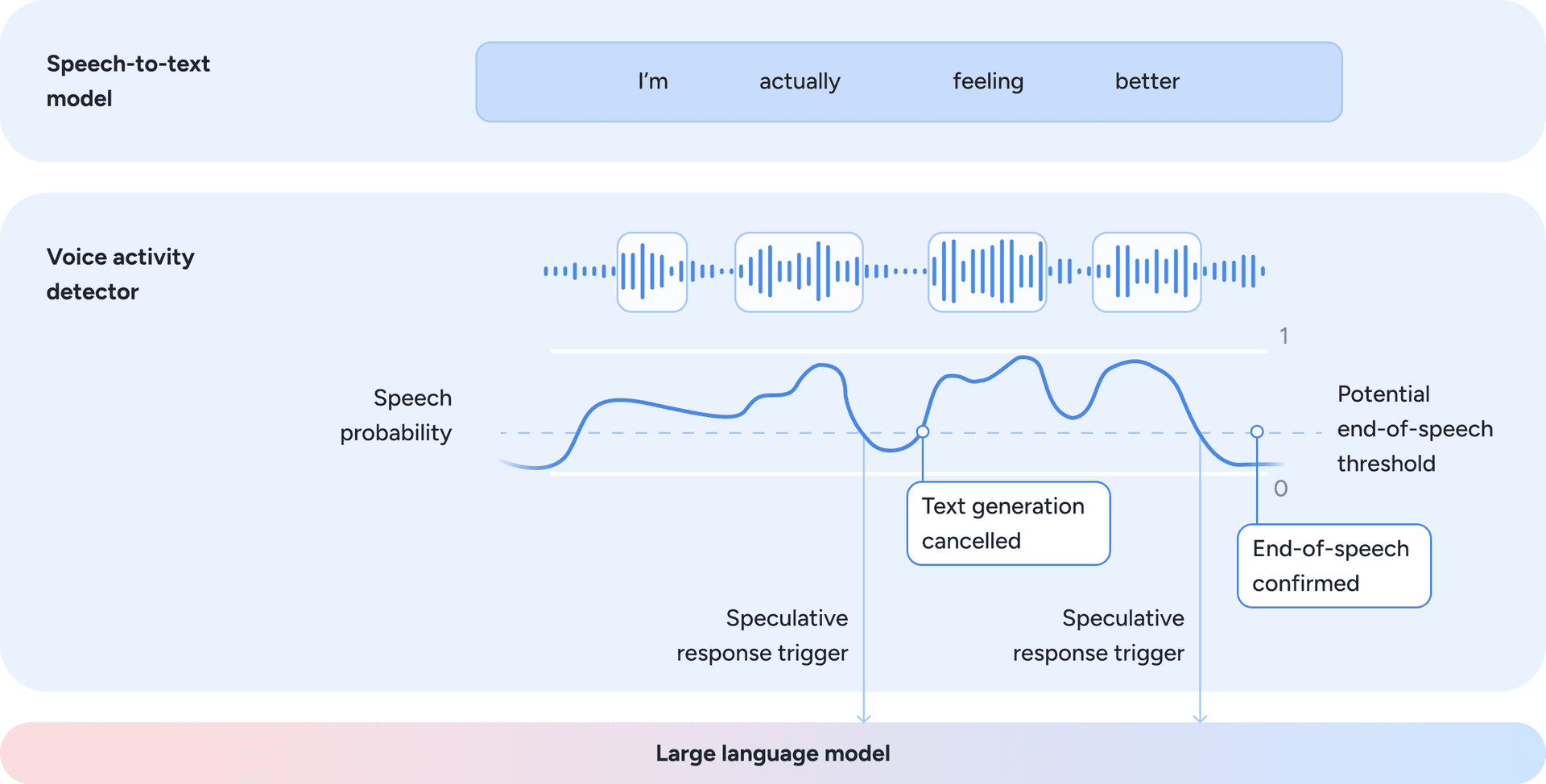
Figure 3: Speculative turn-taking driven by speech probability and potential end-of-speech estimation.
- In parallel, the speech-to-text model operates continuously, producing a textual representation of the audio processed so far. This transcription is always available as contextual input for downstream components. Response generation is not gated on transcription finalization, but on turn-taking readiness inferred from the audio signal.
- The orchestration layer also enables reasoning and speech overlap. Once the language model has generated sufficient response content to ensure coherence, the text-to-speech model begins voicing it. The decision of when to start speaking is based on heuristics derived from linguistic structure, punctuation cues, and response completeness, balancing clarity against latency to maintain a fast, fluid interaction. Figure 4 illustrates how the orchestration layer triggers speech synthesis as soon as sufficient context is available.
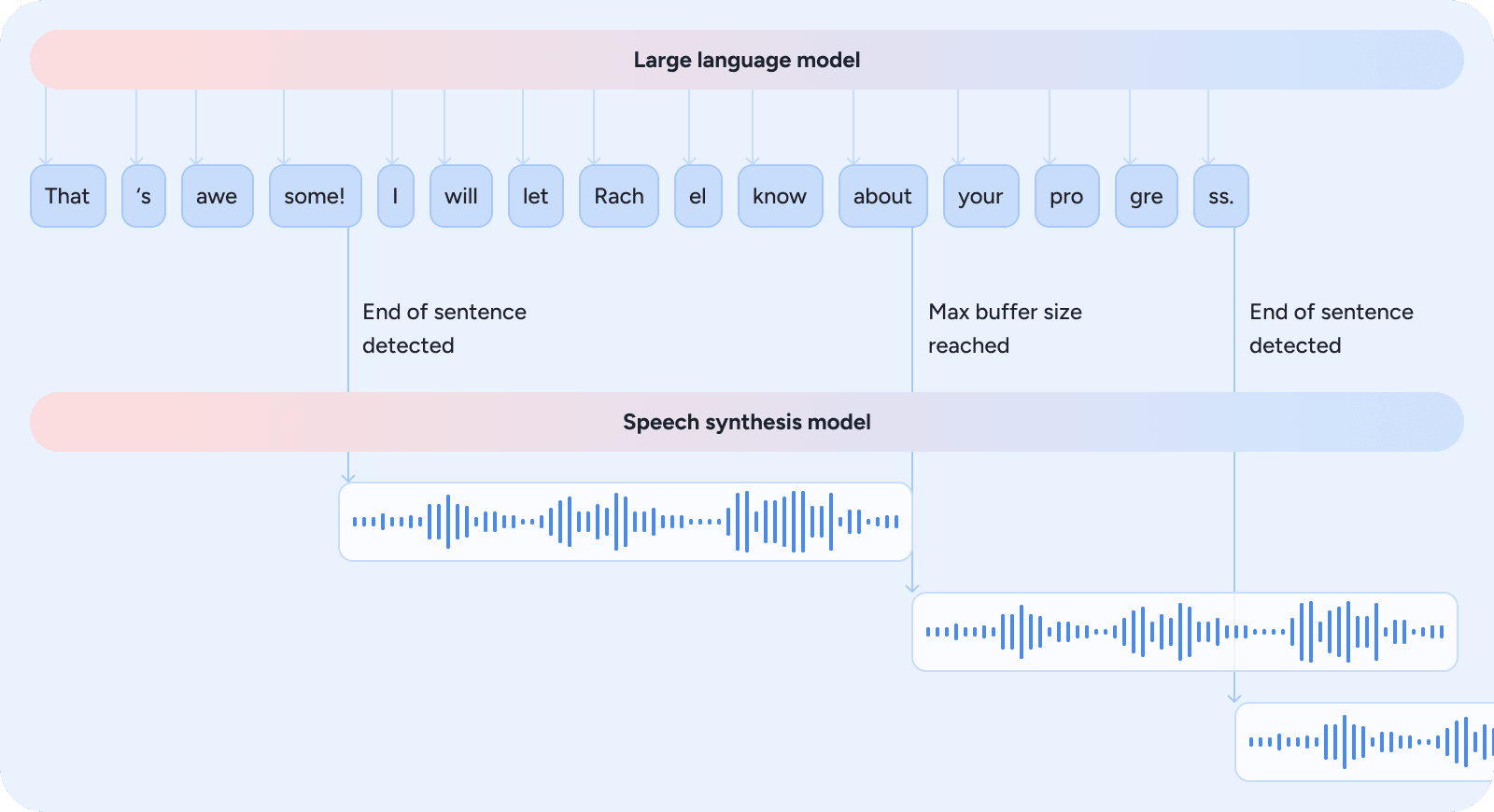
Figure 4: The orchestration layer triggers speech synthesis as soon as heuristics indicate sufficient context for coherent audio, reducing latency while keeping the interaction fluid.
- In addition to overlapping speech synthesis, Phoenix can also retrieve clinical knowledge (8) before text generation and pre execute tools sent as actions (9) for the device. This allows even complex multi-step responses to feel immediate to the member.
These design choices highlight the importance of a modular architecture, which brings practical advantages. It keeps the system transparent (every stage can be inspected), debuggable (issues can be isolated to a single module), and improvable (STT, LLM, or TTS can each be upgraded independently). While end-to-end speech-to-speech models are advancing rapidly, their opaque nature limits the observability and explicit clinical controls that this modular approach provides.
Beyond the processing pipeline itself, the communication layer between Phoenix and the client plays an equally critical role in perceived latency and audio quality. Communication with the client initially relied on WebSockets. This approach proved effective due to its flexibility and maturity in production environments. However, as the system evolved, limitations became apparent at scale and under adverse network conditions. Frameworks such as WebRTC-based LiveKit or orchestration layers inspired by Pipecat address many of these challenges simultaneously:
- Robust, scalable connections: WebRTC is proven at handling variable networks, Network Address Translator traversal, and packet loss while supporting server-side scaling.
- Audio quality and fluidity: Built-in echo cancellation and gain control outperform custom WebSocket implementations, enabling more natural, free-flowing dialogue that supports interruptions and moves beyond a walkie-talkie interaction pattern.
Recognizing these advantages, we have adopted WebRTC to improve resilience and audio consistency.
These architectural decisions directly influence the member experience: when Phoenix responds without hesitation, adapts mid-session, and produces speech that sounds fluid rather than mechanical, it reflects the strength of this voice-first foundation.
How we get to know the member
For Phoenix to feel authentic, it must behave as a continuous presence rather than a collection of isolated exchanges. This is where the Memory System (7) and Vector Store (8) from Figure 2 come in. Each interaction builds on the member’s broader journey, drawing from what has happened both during and between sessions: their progress, preferences, and overall experience throughout the program.
Phoenix achieves this continuity through a dedicated memory system, implemented as a centralized data store indexed by member. Figure 5 provides an overview of how data flows through this system.
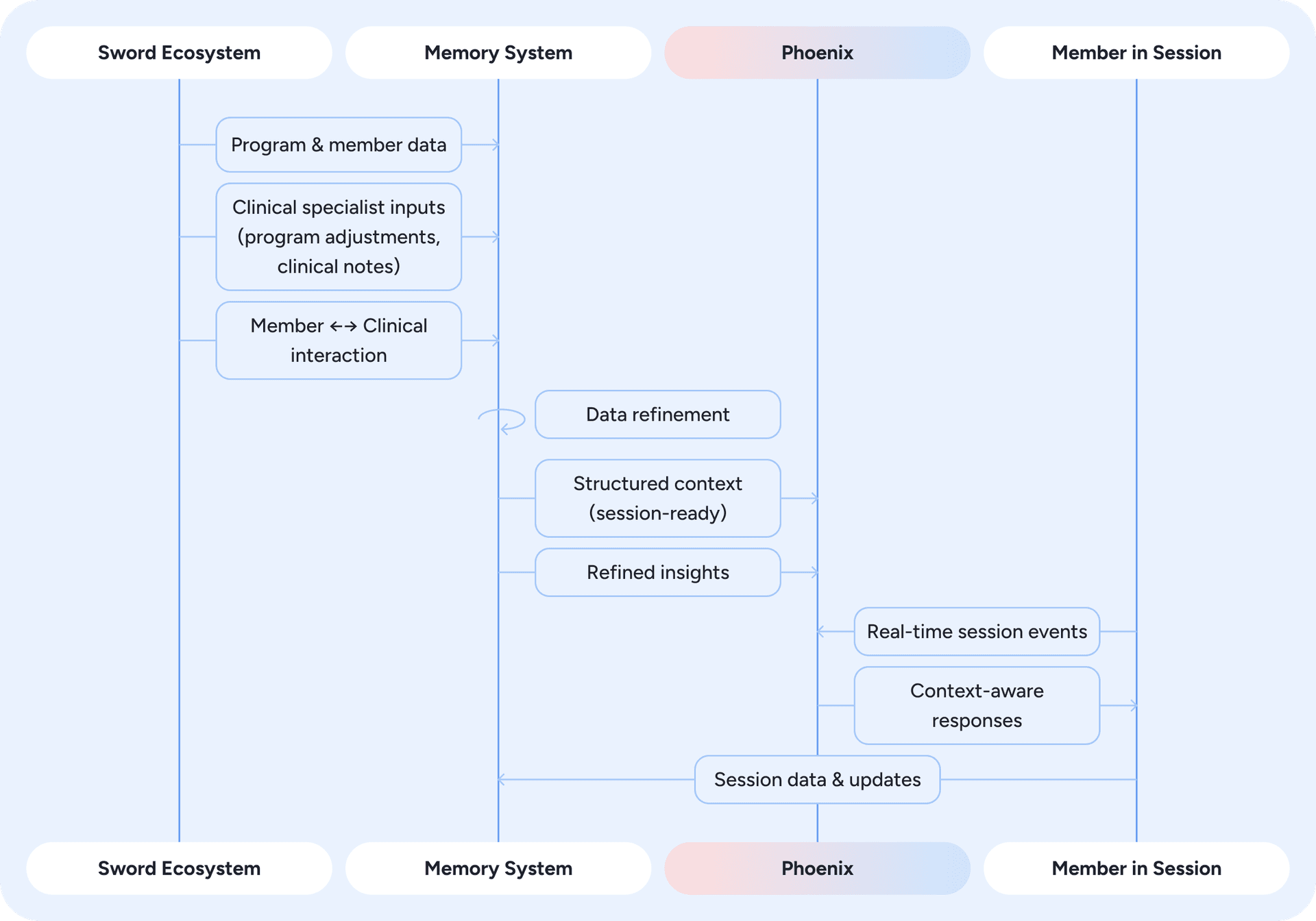
Figure 5: Memory system overview - how data from the Sword ecosystem is refined, stored, and used by Phoenix to deliver context-aware responses in real time.
At the start of each session, Phoenix retrieves structured data that reflects the member's current context. This includes onboarding details, summaries of prior sessions, and program information that defines their treatment path. Phoenix also accesses refined insights generated from events across the Sword ecosystem. These events are captured in real time and processed asynchronously through an event-driven pipeline. Within the memory system, raw signals such as past conversations, clinician notes, and program adjustments are condensed by LLMs into concise, standardized insights stored in natural-language form.
The refinement of information is essential because Phoenix operates in real time and cannot afford lengthy reasoning or large, unfiltered context inputs. Raw data generated across the platform is often verbose, heterogeneous, and unsuitable for fast inference. Simply increasing the context window is not a viable solution, as input length grows, even state-of-the-art models exhibit degraded and uneven performance, leading to increasing non-uniformity across the context [source]. The refinement pipeline addresses this by transforming diverse inputs into brief, interpretable insights that are ready to consume. It removes noise, resolves contradictions, and retains only clinically relevant information, ensuring that long-term context is managed outside the real-time loop and that Phoenix remains fast, coherent, and clinically accurate.
The example below (Figures 6, 7, and 8) illustrates how clinical notes, interactions with the specialist, and program adjustments are transformed into refined memory that Phoenix uses in future sessions. In this case, the member reported mild knee stiffness, the specialist shared an educational resource, and one exercise was updated. The raw inputs, shown as they arrive in the system, highlight exactly why refinement matters: a model operating in real time cannot reason effectively over verbose, heterogeneous data in different formats and structures. The memory summary captures what is actually relevant, providing Phoenix with structured signals that can be surfaced appropriately in subsequent interactions.

Figure 6: Raw data inputs, including clinical notes, member–Clinical Specialist interactions, and program adjustments.
Figure 7: Refined context for Phoenix, produced by the memory system and stored for future use.
Figure 8: Phoenix incorporating the refined context in the next interaction with member.
Phoenix also remains aware of what is unfolding during the session itself, through a real-time event-driven design. A persistent connection with the app streams each meaningful occurrence (a correction in form, a completed or skipped exercise, a clarification request, or the completion of a session milestone) as it happens, keeping Phoenix aware of the session’s context and progress in real time.
By combining structured data, refined insights, and live session context, Phoenix preserves continuity and relevance across sessions, ensuring that interactions remain coherent, personal, and natural over time.
How we ensure clinical safety
Phoenix operates within the context of care, where every interaction shapes how treatment is delivered and perceived. To protect this space, clinical constraints are embedded directly into the system’s core, ensuring that its language and reasoning remain clinically sound and aligned with therapeutic standards. This includes a guardrails layer that runs on every model response, checking outputs against safety rules before they are ever voiced to the member.
Safety, however, starts before the model even responds, through deliberate context engineering. The diagram below (Figure 9) illustrates how Phoenix assembles this context by drawing from clinical data, member information, system inputs, and available tools, selecting only what is relevant for the current turn. This forms the active context window: a carefully constructed snapshot designed to keep each model invocation grounded in the correct blend of clinical guidance, member state, and safety constraints.
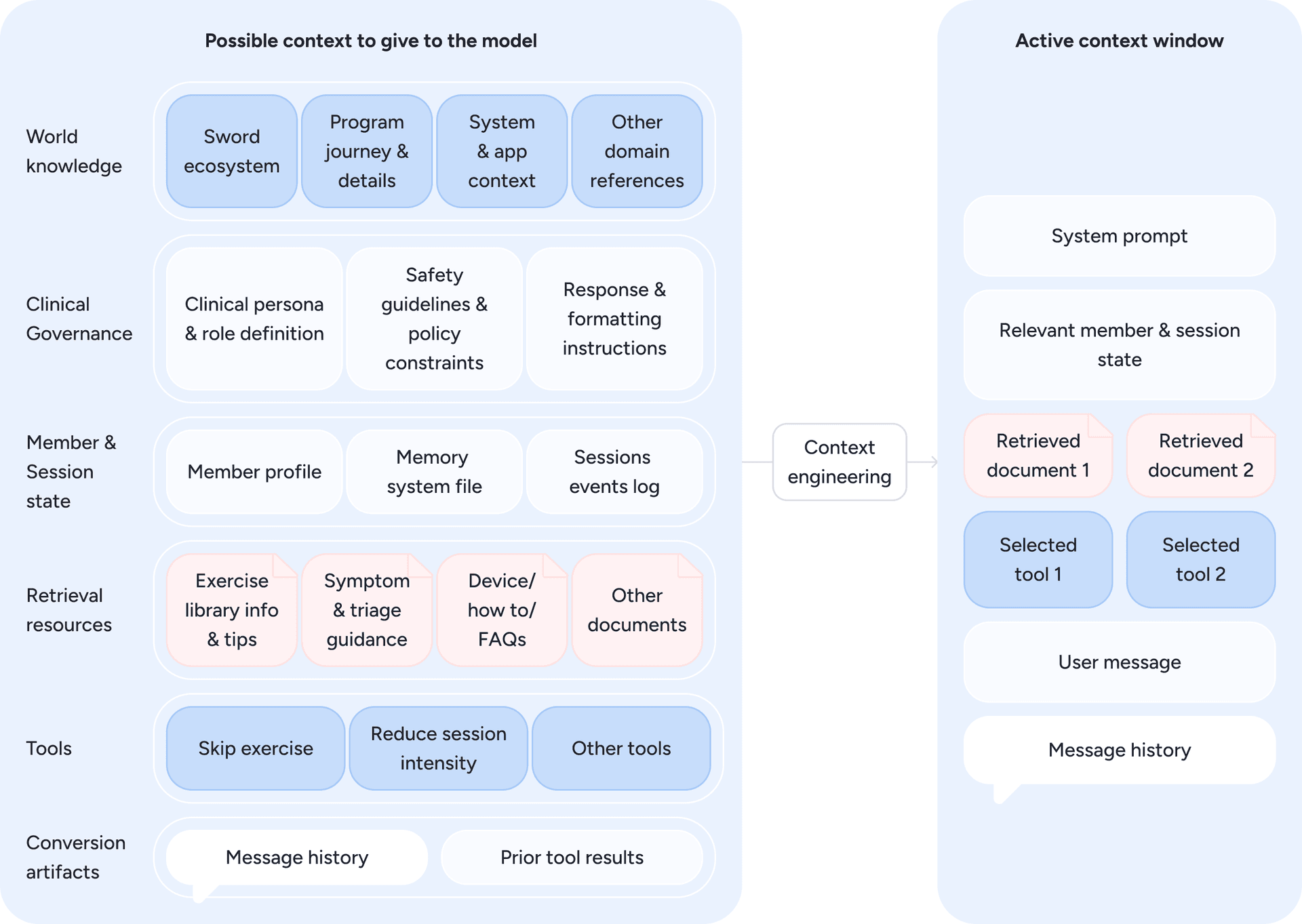
Figure 9: From all possible inputs to the model, only the most relevant elements are selected, forming the active context window that guides Phoenix’s real-time reasoning. Diagram inspired by Anthropic diagram on “Effective context engineering for AI agents” [source]
Phoenix is grounded in Sword’s proprietary clinical knowledge bases. A Retrieval-Augmented Generation (RAG) pipeline acts as a dynamic context builder, enriching the model’s context by surfacing evidence-based information relevant to each moment, such as guidance for a particular exercise or tailored suggestions when a member reports a specific symptom or behaviour, as illustrated in Figure 10. The system combines hybrid search with dense embeddings to retrieve the most relevant content, ensuring that each response is supported by accurate, up-to-date knowledge. This approach complements the model’s context and enables Phoenix to reason within clinically verified information.
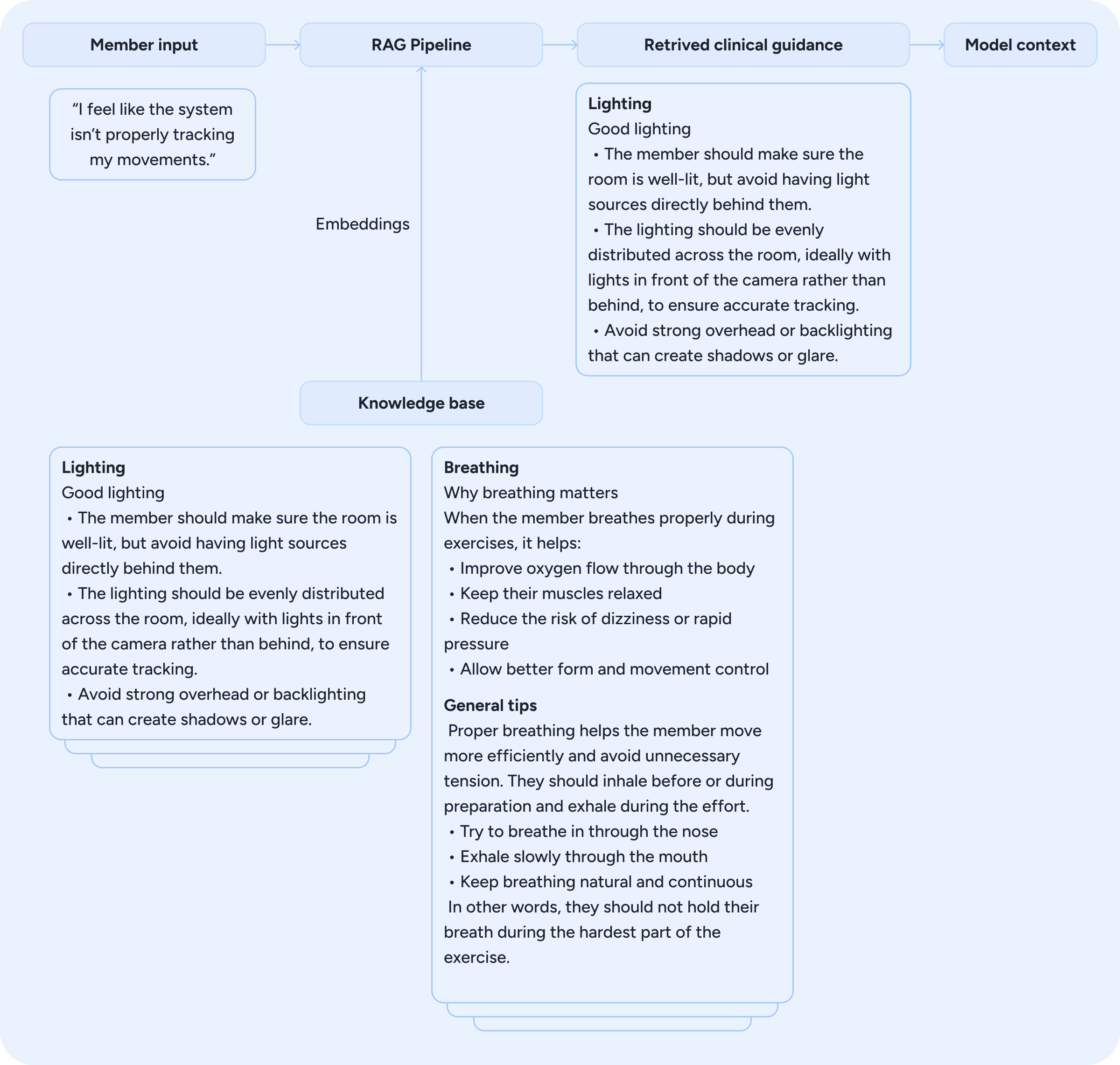
Figure 10: Retrieval-Augmented Generation pipeline surfacing clinically verified guidance based on member input.
Ensuring safety always involves trade-offs. Large language models excel at open-ended reasoning, but in healthcare, some of that flexibility must be constrained to preserve precision and consistency. Phoenix is designed to navigate this balance: expressive enough to engage naturally, yet never improvising beyond what is clinically approved. When a situation falls outside the expected therapeutic context, automated systems flag the interaction for review, a process described in the next section.
Phoenix ←→ Clinical Specialist loop
The collaboration between Phoenix and the Clinical Specialist is what turns conversational intelligence into true clinical care. Every interaction Phoenix has with a member feeds into a broader ecosystem designed to keep the specialist in the loop while scaling their reach.
After each session, Phoenix’s interaction data is condensed into structured insights and actionable follow-ups that populate the clinician’s Feed, Sword’s central hub for program management (Figure 11). Through it, specialists gain a clear view of how the session unfolded and what steps may be needed to move the treatment forward.
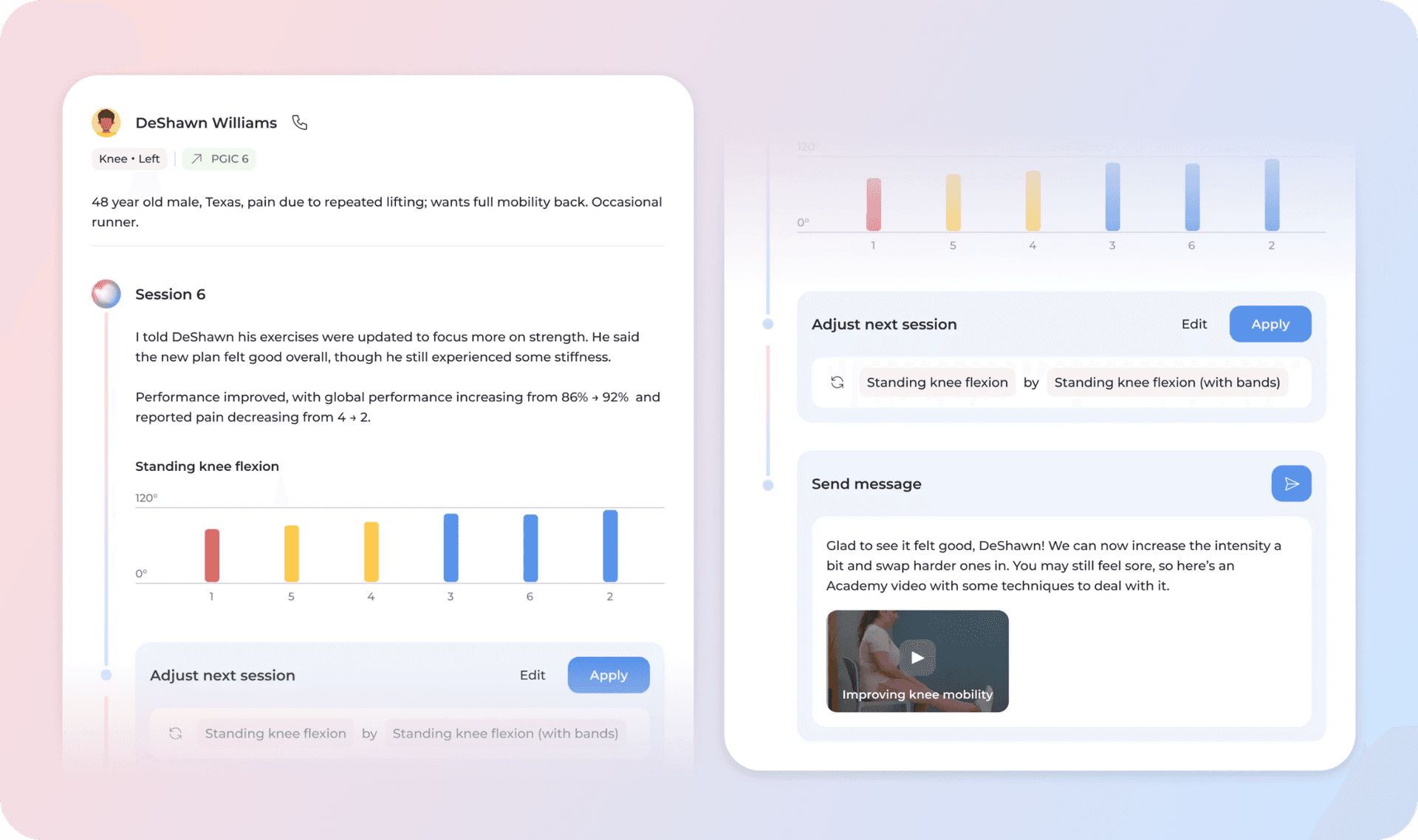
Figure 11: The clinician’s Feed, where Phoenix’s session insights, recommendations, and member progress are surfaced for review and action.
Phoenix brings together context from across the member's journey: their clinical profile, interactions with the specialist, session data, and broader engagement patterns. Using this information, Phoenix runs a series of agents that interpret what these signals mean clinically. These agents, including the urgency classifier, session analyser, and clinical planning and engagement agents, help determine the most appropriate next action for the member and support the insights surfaced in the Feed. They combine LLM-based reasoning with classifiers that identify clinically relevant signals.
One of the most valuable sources of information is what Phoenix surfaces during real-time sessions. Feedback captured in the moment, from reports of discomfort to signs of low motivation or fatigue, enables Phoenix to recommend actions to the Clinical Specialists, such as adapting treatment plans or guiding how they engage with members between sessions. This point-of-care information collection helps specialists stay fully informed and supports clinical alerts and timely, personalized follow-ups.
Evaluation and validation
Phoenix operates in a regulated healthcare environment. Meeting clinical safety and regulatory standards is achieved through rigorous validation of every change before release and continuous monitoring of live performance (including member conversations) once deployed.
Offline evaluation
The evaluation process adapts to the scope of the change. For new behaviors or major releases, clinical specialists are involved from the start, defining safety boundaries and reviewing outputs for therapeutic accuracy. Continuous improvements follow shorter cycles but are held to the same clinical standards.
At the core is Gondola, our internal platform where clinical and product experts review Phoenix’s responses and test them across both common and edge-case scenarios. Insights gathered in Gondola feed into an evaluation framework that combines human judgment with automated assessment. Clinicians help create datasets, define rubrics, and label examples that allow us to refine automated evaluators over time. Each case is defined with clear success criteria so that quality can be measured consistently.
The evaluation dataset includes both real and synthetic examples. Real data is stratified from live interactions to represent diverse member experiences, covering different program stages, conversation types, and user profiles. Synthetic cases are generated through simulation using LLMs to simulate member profiles and long-tail scenarios. This approach ensures coverage across both frequent and rare cases, helping us test Phoenix beyond what commonly appears in production.
Within this framework, evaluators fall into two main types: code-based and LLM-as-Judge. Code-based evaluators perform objective checks, such as detecting emergency keywords or enforcing rules like response length. LLM-as-Judge capture nuances that cannot be measured through code alone, including empathy, tone, repetition, or appropriate refusal to give medical advice. These LLM-as-Judges are calibrated through human annotation, developed and refined to maximize agreement with human expert assessment, ensuring they capture the same clinical nuances that manual review would.
With this automated suite in place, we run offline evaluations that replay real interactions under different configurations, such as updated prompts or new model versions, to assess quality before any change reaches production.
Taken together, this evaluation framework supports baseline assessments for new features, quality scoring after updates, and regression testing, ensuring every release improves Phoenix while preserving the trust clinicians and members rely on.
Online Evaluation
Once deployed, Phoenix remains under continuous evaluation. Automated systems categorize and flag interactions that may require review, ensuring clinicians focus on high-risk or ambiguous cases. In parallel, random clinical audits of sampled conversations verify that Phoenix's behavior stays within therapeutic and safety requirements, a key compliance practice in clinical settings.
Beyond manual oversight, online evaluations score a sample of live interactions using the same evaluation suite that runs offline, monitoring Phoenix’s behavior and flagging regressions as soon as they appear (Figure 12). If metrics fall below predefined thresholds, the team is prompted to intervene, ensuring issues are addressed before they impact care.
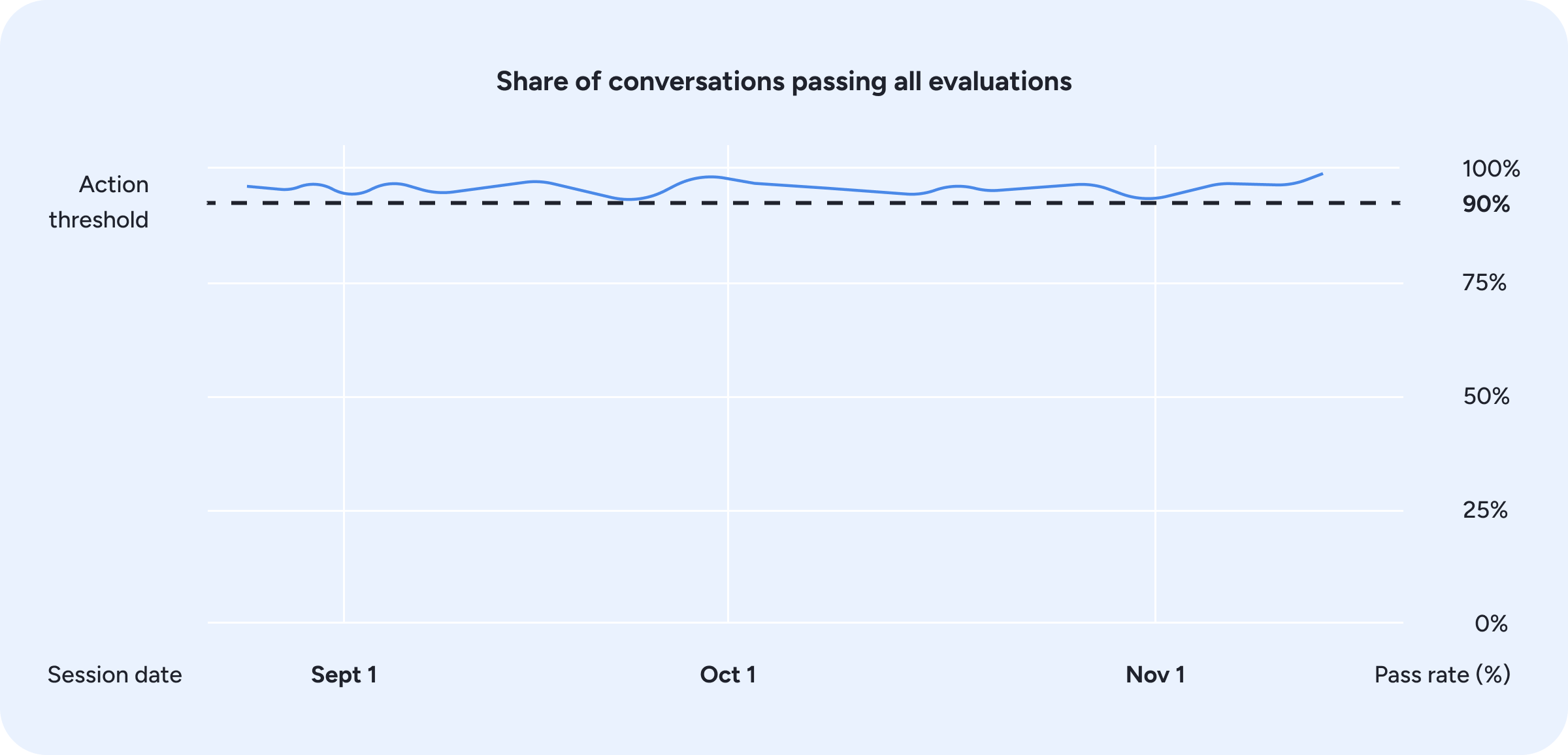
Figure 12: Online evaluation pass rates over time, with automated monitoring triggering action when performance approaches the threshold.
The evaluation process continues to evolve, as new examples encountered in production feed back into dataset expansion and rubric refinement, closing the loop between live performance and pre-release validation.
Key learnings and areas of ongoing work
What we have learned
Our experience building Phoenix real-time conversational experience surfaced several engineering principles that now anchor our approach. We covered multiple topics throughout the article, but a few key learnings are worth highlighting:
- Reliable foundations matter. Early iterations relied on WebSockets, which worked well for rapid development but revealed clear limitations under challenging network conditions and at scale. This reinforced the need for a transport layer designed for real-time, bidirectional communication. These constraints set the stage for our ongoing shift toward WebRTC.
- Prioritize context over prescriptive rules. We observed that models perform best when supported by clean, well-curated context produced through deliberate context engineering rather than long prompt instructions or rigid rule lists. High quality inputs consistently produced safer and more natural responses than expanding the instruction set or increasing constraints.
- Evaluation is critical for both velocity and safety. A test-driven workflow anchored in evals allow us to iterate quickly while maintaining reliability. Continuous evaluation surface failure modes early, guide model and pipeline adjustments, and provide visibility into Phoenix’s behavior in production-like conditions.
- Clinical teams must be co-creators, not reviewers. Involving clinical experts from the earliest stages of design, not as an afterthought, has been essential to building a system that is both safe and effective. Clinicians define what good care looks like, shape evaluation frameworks, and validate behavior across diverse scenarios. When clinical input comes late, it becomes corrective rather than foundational, and the cost of misalignment grows significantly.
What we are working on
Phoenix's voice experience is strong, but we're just getting started. From a product perspective, we're expanding Phoenix's role within the flow of the session. As an active extension of the clinical team, it will increasingly assist during exercise execution and use visual-language model capabilities to interpret the member and the scene around them. These advances open new possibilities. Phoenix may tailor cues to lighting or positioning, provide feedback when clothing interferes with tracking, and proactively refine its guidance using additional visual context.
An improved speech model will also play a central role. By fine-tuning speech models to reflect Sword’s conversational style, Phoenix can sound more natural, empathetic, and aligned with our brand of care. At the same time, leveraging open-source alternatives can reduce latency and cost while increasing system flexibility.
We’re also exploring deeper personalization. Each member interacts differently, and Phoenix should learn to reflect that by adjusting how often it intervenes, how concise or encouraging it is, and how its communication evolves throughout the member’s journey and personal preferences. These ideas build on the same principle that drives human care: being attuned to who is on the other side.
In parallel, we are focusing on reducing the “LLM-ness” of responses, such as over-hedging, generic empathy, or verbose phrasing. We are improving how clinical tone and stylistic controls are embedded in the model, with the goal of producing responses that are more coherent, warm, and precise.
Conclusion
Building Phoenix has been a process of extending Sword’s clinical expertise across the entire member journey. It reflects a shift from episodic, human-dependent care to continuous, intelligent support that understands progress, adapts to needs, and remains aligned with therapeutic goals over time.
In this post, we focused on the real-time conversational experience, where Phoenix must respond immediately, stay context-aware, and operate within clinical guidelines. By combining robust guardrails, structured memory, and domain-specific knowledge with a fast, modular speech stack, we have created a system that feels natural while remaining clinically precise.
Looking ahead, advances in personalization, multimodal understanding, and further post-training will allow Phoenix to adapt tone, context, and reasoning even more effectively to each member and moment.
Ultimately, Phoenix represents more than a technical achievement. It is a step toward scaling Sword’s mission of using artificial intelligence to deliver high-quality care to people everywhere.
Acknowledgements
Written by Diogo Gonçalves in collaboration with Clara Matos, supported by the solution built by Diogo Gonçalves, Miguel Constantino Cruz, Carolina Pinto, Alexandra Oliveira, Luís Silva, Catarina Farinha, Jorge Ribeiro, Clara Matos, Ivo Gabriel, and Luís Ungaro.
This work reflects the collective effort of multiple teams across Sword Health who make Phoenix possible. Special thanks to Thrive, Bloom and Move tech and product teams.