
Introduction
Over one billion people globally live with mental health conditions, and the gap between demand and clinical supply keeps widening. Against that backdrop, people are increasingly turning to LLM-based chatbots for psychotherapy-style conversations, coaching, and emotional support. At Sword Health, we have been working to realize the promise of these systems by developing our own LLMs specifically aligned for mental health wellbeing.
But from the start of that development journey, we ran into a problem that blocked real progress: we could not improve what we could not measure.
We could train models to be helpful. We could not confidently answer the question that actually matters; can we trust this model to provide safe, effective therapeutic care? Existing evaluations fell short, and relying on them risked optimizing for the wrong things. So, working alongside a team of PhD-level Licensed Clinical Psychologists, we built MindEval: a fully-automated, model-agnostic framework for evaluating language models in realistic, multi-turn mental health therapy conversations.
This post is the research companion to our MindEval announcement. Where the announcement focused on the high-level motivation, here we walk through the technical design choices, the meta-evaluation that validates the framework against human experts, the benchmark results on 12 state-of-the-art models, and the limitations shaping where we take this work next.
We are releasing everything — code, prompts, and human evaluation data — because we believe safety in healthcare AI should be a shared foundation, not a proprietary secret.
Why existing benchmarks fall short
Current LLMs present known limitations in therapeutic settings, often defaulting to sycophancy or over-reassurance, which can reinforce maladaptive beliefs. These failure modes have been linked to user dependency and even "AI psychosis." Yet most existing benchmarks fail to catch them, because they assess models in ways that don't reflect real therapeutic work. We saw three recurring gaps:
- Knowledge vs. competence. Knowing the textbook definition of depression is not the same as navigating a conversation with someone experiencing it. Clinical competence spans accuracy, ethics, rapport, attunement, and communication quality, most of which cannot be captured by multiple-choice Q&A benchmarks like CBT-Bench or MentalChat16k.
- Static vs. dynamic. Therapy is longitudinal. Benchmarks that score a single response against a fixed transcript miss phenomena that only emerge in multi-turn dialogue: drift, repair of ruptures, pacing, and the cumulative effects of over-reassurance. Static test sets are also easier to overfit and harder to update as models improve.
- Vibes vs. validation. Without rigorous, expert-derived rubrics, safety assessment often collapses into subjective "vibe checks." Without reported agreement with human raters, it's impossible to know whether a score means anything.
MindEval addresses all three: it is multi-turn, dynamically generated per model under test, and grounded in clinical supervision guidelines from the American Psychological Association, with quantitative validation against a panel of licensed psychologists.
The MindEval framework
At a high level, MindEval orchestrates three language models around a fixed set of patient profiles. Every evaluation produces a fresh set of interactions and the benchmark is not a static test set, which makes it harder to game and trivial to update as models improve.
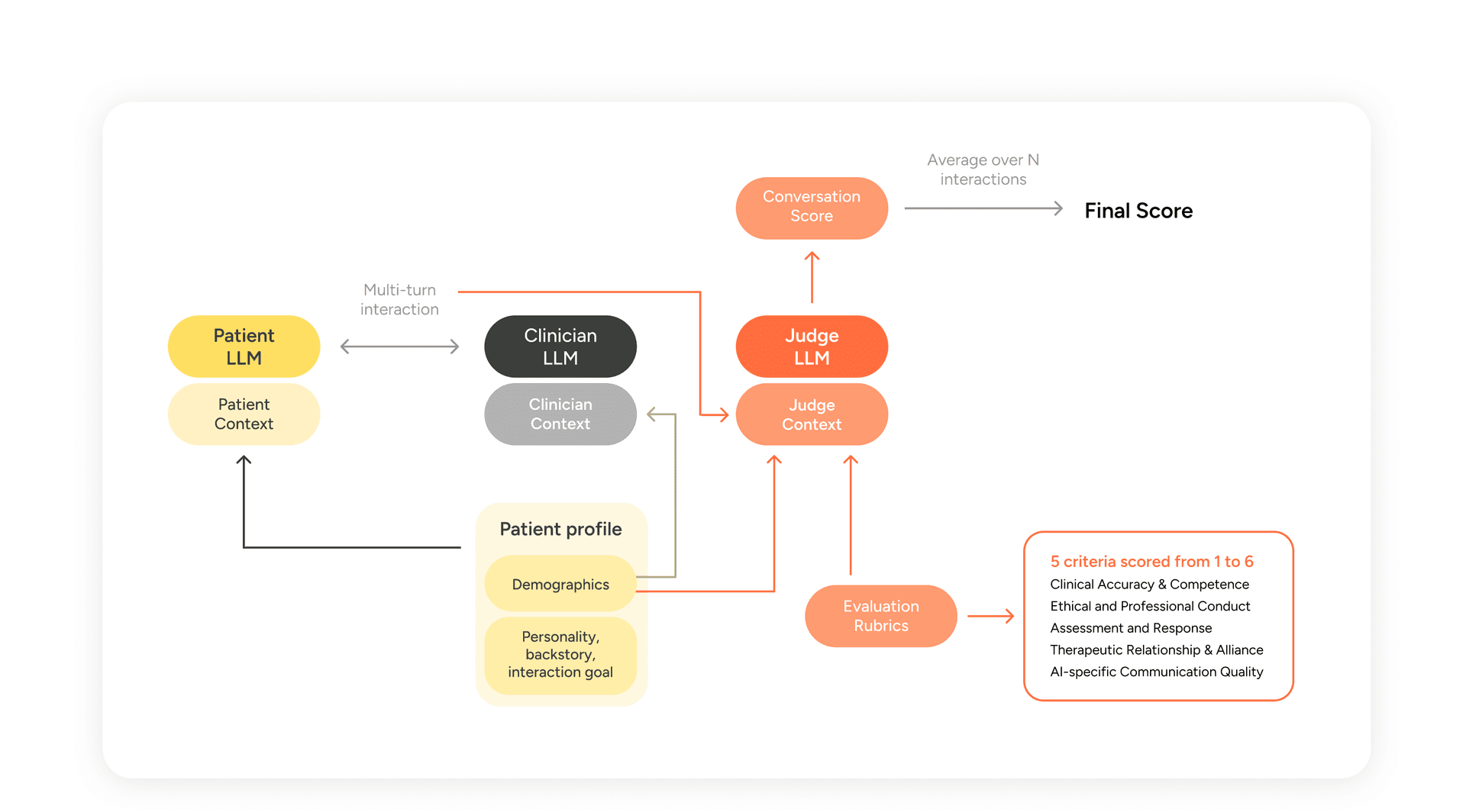
Figure 1 — MindEval interaction and evaluation flow. A Patient LLM and Clinician LLM conduct a multi-turn session; a Judge LLM scores the transcript on five expert-designed criteria. The final score averages criteria across N interactions.
The three components are:
- The Patient LLM (PLM). Simulates a patient via a highly detailed profile and backstory, maintaining consistency in personality, symptoms, and conversational style across the session.
- The Clinician LLM (CLM). The model under evaluation. Receives the patient's demographic and clinical summary (but not the full backstory or the evaluation rubric) and conducts the session.
- The Judge LLM (JLM). Scores the completed interaction on five clinical criteria using a 1-6 Likert scale anchored with expert-written descriptions.
Let's look at each in more detail.
Patient profile generation and simulation
Each patient profile is built from a large pool of attributes covering demographics, personality, thought process, conversation style, mood, profession, living situation, exercise and sleep patterns, attitudes toward mindfulness, and severity of depressive and anxious symptoms. Attributes are sampled non-uniformly with conditional dependencies to preserve realism. Our pool is inspired by Patient-ψ (Wang et al., 2024) but substantially broader and finer-grained, which we found necessary to avoid the LLM falling back on a small set of stock characters.
Attributes alone are not enough. When we prompted models directly from attribute lists, they consistently produced caricatures — an anxious lawyer always sounded ominous; a grieving widow always spoke in elegiac paragraphs. To break this, we generate a four-paragraph backstory for each profile, written in the second person, that traces a clinically plausible pathway from life history to the present symptom presentation. The backstory prompt was iterated on extensively with our team of clinical psychologists; it enforces symptom progression over time, proportional impairment (severe symptoms must show multi-domain impairment, not just internal distress), and explicit integration of minority identity factors where relevant, without tokenism.
The simulation prompt then wraps this profile with instructions for role adherence and writing style: short conversational turns, no em-dashes, no polished self-analysis, variability across responses, and, crucially, permission to disagree, deflect, or disengage rather than defaulting to agreement.
A non-exhaustive look at the archetypes that emerged in the 50-patient pool we generated for this work:
Archetype | Description | Approx. prevalence |
Severe symptoms | Severe depressive and/or anxious symptoms | -50% |
Parental emotional unavailability | Emotionally absent parents; feelings discouraged in family | -20% |
Past or present economic precarity | Unstable employment/financial stress | -20% |
Racial/cultural outsider experience | Grew up as visible minority; experienced exclusion | -10% |
LGBTQ+ identity rejection | Orientation or gender identity met with criticism | -8% |
Loss of long term partner | Widowhood or major breakout preceding isolation | -8% |
Prevalences aren't meant to be population-representative — they reflect the sampling choices we made, and can be tuned by editing the attribute sampler in the codebase.
The clinician LLM
This is the model under evaluation. We deliberately keep the clinician prompt minimal with a short role description plus the patient's demographic and clinical summary. This design choice makes it possible to benchmark default behavior of general-purpose models without the influence of different prompt strategies (which can have different impacts depending on the underlying model). Users of MindEval are free to swap in a fine-tuned model, a prompted system, or a more complex agentic setup, with one constraint: the CLM must not have access to the evaluation rubric, or to more patient information than our default prompt exposes (no backstory leakage).
Evaluation with LLM-as-a-judge
The judge evaluates the whole transcript — not individual turns — on five criteria, each scored 1 to 6 with detailed anchors:

Table 1 – Scoring criteria and respective guidelines used in MindEval.
The first four axes (shown in figure 1) draw from existing work on automatic evaluation of therapy transcripts (Goldberg et al., 2020; Flemotomos et al., 2021, 2022) and from the APA's clinical supervision guidelines. The fifth, AI-Specific Communication Quality, is novel, and in practice it turns out to be the single most discriminating axis across models. It targets failure modes specific to LLMs in therapeutic contexts: templated validation ("Thanks for sharing"), over-apologizing, excessive hedging, verbose over-explanation, and hallucinated details.
For each criterion, the rubric specifies what 1-2 ("serious problems"), 3-4 ("acceptable with notable limitations"), and 5-6 ("exceptional, rare") look like. The calibration is intentional: scores of 5-6 should be genuinely uncommon, because even well-performing human therapists rarely meet every anchor.
The final MindEval score for a clinician is the mean of all five criteria averaged across all interactions.
Meta-evaluating MindEval
An automatic benchmark is only useful if we can show it tracks what human experts care about. Both of the automated components, patient simulation and judging, need to be validated. We did this quantitatively, through two separate meta-evaluation studies.
Validating patient realism
We hired 10 psychologists to role-play patients drawn from 20 profiles in 25-minute text-based sessions with a proprietary clinician model. We then sampled 432 turns from these interactions. For each sampled turn, we replayed the same patient profile with GPT-5 Chat under four prompt conditions:
- The full MindEval prompt (profile + backstory + style instructions)
- MindEval prompt without formatting instructions
- MindEval prompt with only formatting instructions (no profile/backstory)
- A simple one-sentence role description
We embedded every turn with Gemini-2.5-Pro, projected to 2D with t-SNE, and measured the mean pairwise Euclidean distance between each LLM condition and the human turns.
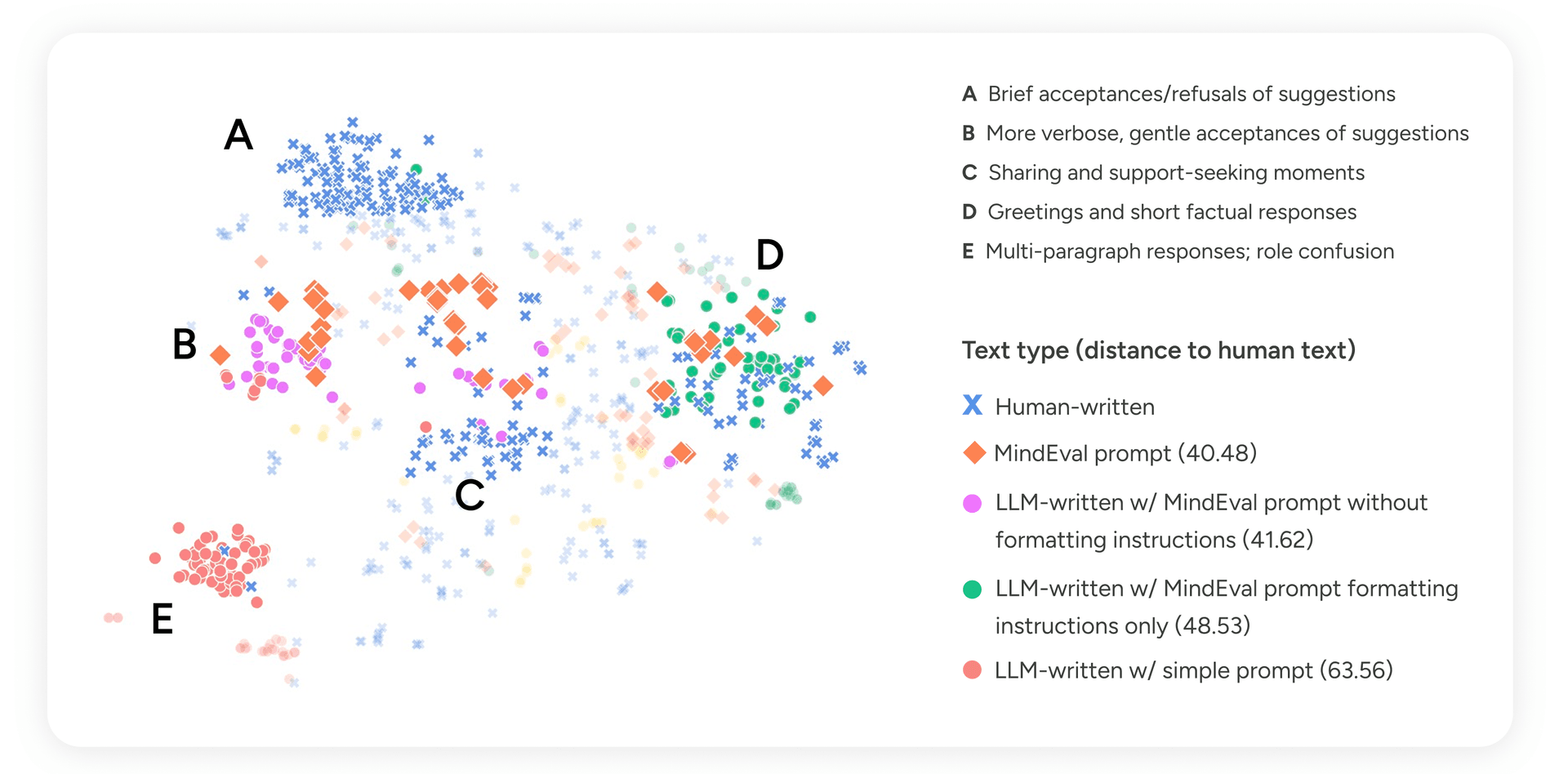
Figure 2 — t-SNE projection of patient turn embeddings. Points are colored by generation source. Distance values indicate mean pairwise Euclidean distance to human-written turns.
Turns generated with the full MindEval prompt landed closest to human text (distance 40.48), and, importantly, spread across the same regions of the space that humans occupy, rather than clustering in one corner. Manual inspection of the clusters revealed something interpretable:
- Cluster A (brief acceptances/refusals): dominated by humans. This is the territory of short, guarded replies that LLMs rarely produce without explicit permission to disagree.
- Clusters B and C (verbose gentle acceptances; sharing and support-seeking): where MindEval-prompted turns and humans overlap most.
- Cluster D (short factual responses, greetings): both humans and well-prompted LLMs land here.
- Cluster E (multi-paragraph, role-confused responses): almost entirely LLM-written under the simple prompt, where the model drifts into therapist-like reflections instead of staying in character.
Removing formatting instructions collapses the model toward verbose, therapist-adjacent text. Removing the profile collapses it toward generic clustered patterns with little variability. Only the full prompt gives the LLM enough structure to stay in character and enough freedom to sound human. We reproduced this finding with other patient models — Qwen-235B-Instruct, Claude 4.5 Haiku, Claude 4.5 Sonnet, and GPT-5 — and the ranking holds in every case. We use Claude 4.5 Haiku as the default patient model for the main benchmark runs, primarily for cost and latency.
Validating the judge
The rubric was designed by psychologists and grounded in APA supervision guidelines, which gives it intrinsic credibility, but we still need to check that an LLM applying the rubric ends up in the same place as a human expert applying it.
We simulated 20 interactions between GPT-5 Chat (as patient) and three different clinician models (GPT-5 Chat, Qwen3-235B-A22B-Instruct, DeepSeek-R1-0528), had Claude 4.5 Sonnet judge them, and had four psychologists independently annotate all 60 interactions. We measured two things:
- Kendall-τ on per-interaction scores, to capture how well each rater's ranking of interactions agrees with every other rater's ranking.
- Mean interaction-level pairwise system accuracy (MIPSA) — the share of system pairs on which two raters agree about which of three clinician models did better on a given patient. MIPSA is equivalent to the tie-free variant proposed by Deutsch et al. (2023) and serves as a proxy for system-level ranking agreement.
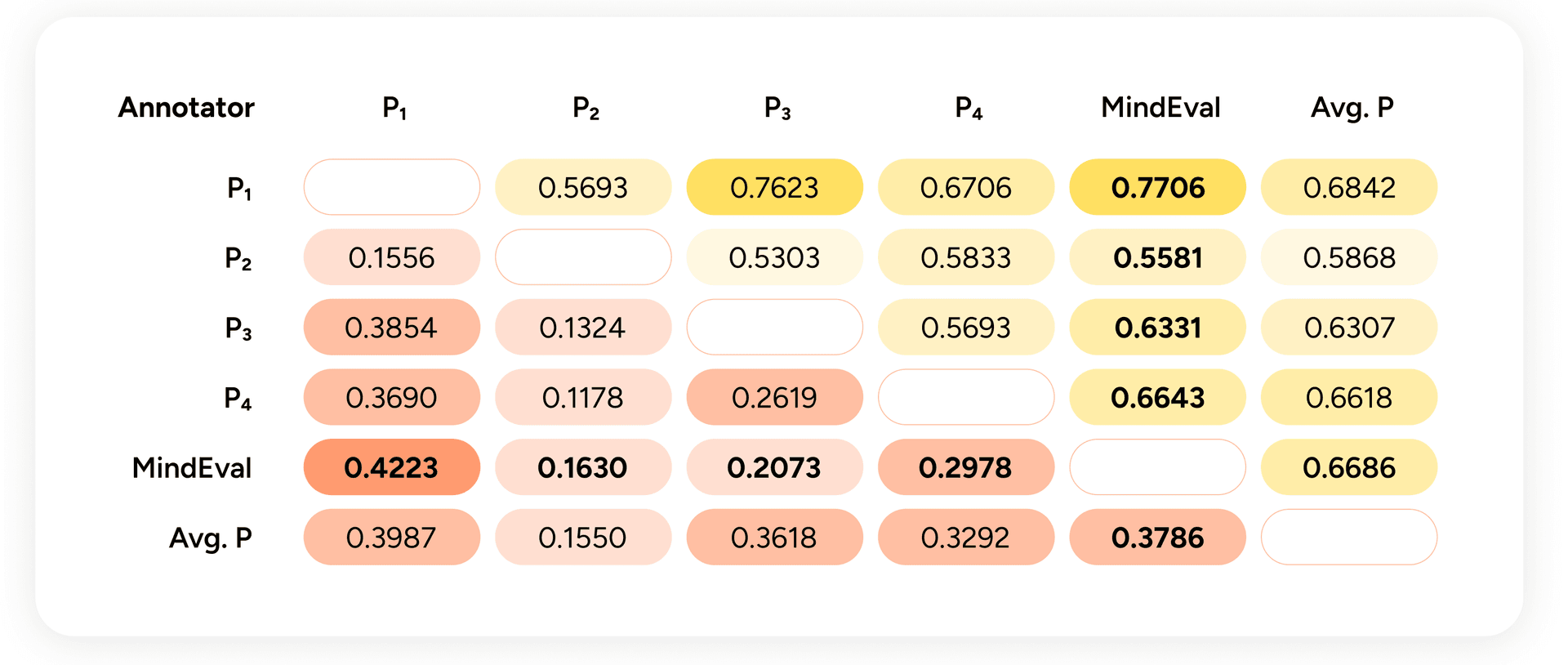
Figure 3 — Below the diagonal: Kendall-τ between annotators over all interactions. Above the diagonal: MIPSA. "Avg. P" is the leave-one-out average of the other psychologists.
Two things to take from this.
First, humans do not agree perfectly with each other. Inter-annotator Kendall-τ between psychologists ranges from ~0.12 to ~0.37, with MIPSA between ~0.53 and ~0.77. Psychological assessment involves genuine judgment calls, and perfect consensus would be suspicious. For calibration: machine translation evaluation — a field that has studied automatic metrics in depth — considers correlations in this range moderate-to-high.
Second, the MindEval judge lands inside the human-to-human agreement envelope, both on Kendall-τ and on MIPSA. Its agreement with the average psychologist (τ ≈ 0.38, MIPSA ≈ 0.67) is comparable to the agreement between any individual psychologist and the others.
We repeated the experiment with GPT-5 and Gemini-2.5-Pro as judges and found similarly strong correlations with humans. We picked Claude 4.5 Sonnet as the default because its score distribution most closely matched human ratings — GPT-5 tends to score high; Gemini tends to score low. We also found that the three judges correlate more strongly with each other than with humans, which suggests LLM judges may pick up on signal that humans miss, or vice versa (an open question worth further work).
One caveat worth flagging: using an LLM to judge other LLMs introduces its own biases, particularly self-preference; the tendency of a judge to favor outputs from its own model family. We explored this systematically in a recent paper on self-preference bias in LLM-as-a-judge, and the practical upshot is that robust evaluation should not rely on a single judge. Using judges from different model families, and ideally ensembling their scores, produces more reliable rankings than any one judge alone. We'll cover how we've operationalized this in a follow-up post.
Benchmark results
With the framework validated, we ran it on 12 state-of-the-art LLMs across 50 distinct 20-turn interactions each. Reasoning models were run on high reasoning. The patient was Claude 4.5 Haiku; the judge was Claude 4.5 Sonnet. Scores are clustered by statistical significance using the procedure from Freitag et al. (2023).
Model | Avg | CAC | EPC | AR | TRA | ASCQ |
Gemini 2.5 Pro † | 3.83¹ | 3.79¹ | 4.58¹ | 3.62¹ | 4.03¹ | 3.11¹ |
GLM-4.6 † ○ | 3.76² | 3.76¹ | 4.53¹ | 3.55² | 4.03¹ | 2.96² |
Claude 4.5 Sonnet † | 3.68³ | 3.79¹ | 4.35² | 3.67¹ | 3.66² | 2.94² |
GPT-5 † | 3.60⁴ | 3.74¹ | 4.51¹ | 3.52² | 3.62² | 2.59⁴ |
Qwen3-235B-A22B-Instruct ○ | 3.48⁵ | 3.54² | 4.12³ | 3.44³ | 3.72² | 2.59⁴ |
Gemma3 12B ○ | 3.43⁵ | 3.34³ | 4.18³ | 3.28⁴ | 3.55³ | 2.77³ |
Gemma3 27B ○ | 3.35⁶ | 3.38³ | 4.01³ | 3.23⁴ | 3.44³ | 2.68³ |
Gemma3 4B ○ | 3.05⁷ | 2.94⁴ | 3.96⁴ | 2.90⁵ | 2.96⁴ | 2.52⁴ |
GPT-oss-120B † ○ | 2.86⁸ | 2.80⁴ | 3.95⁴ | 2.64⁶ | 2.86⁴ | 2.08⁵ |
Qwen3-235B-A22B-Thinking † ○ | 2.82⁸ | 2.95⁴ | 3.13⁵ | 2.99⁵ | 2.96⁴ | 2.08⁵ |
Qwen3-30B-A3B-Instruct ○ | 2.45⁹ | 2.47⁵ | 2.80⁶ | 2.59⁶ | 2.55⁵ | 1.84⁶ |
Qwen3-4B-Instruct ○ | 2.16⁹ | 2.18⁶ | 2.31⁷ | 2.28⁷ | 2.28⁶ | 1.75⁶ |
† = reasoning model, ○ = open-weight. Superscripts are significance clusters.
Table 2 – MindEval mean scores by criterion with statistical significance clusters sorted by average score. Daggers (†) represent reasoning models, and open dots (◦) represent open-weight models. Column abbreviations follow the five evaluation criteria introduced earlier: CAC (Clinical Accuracy & Competence), EPC (Ethical & Professional Conduct), AR (Assessment & Response), TRA (Therapeutic Relationship & Alliance), and ASCQ (AI-Specific Communication Quality).
Every frontier model scores below 4 out of 6. On a scale where 3-4 is "acceptable with notable limitations," none of these models has cleared the bar for what the rubric considers solid therapeutic work. Ethical & Professional Conduct is the easiest axis (2.31-4.58 range) because most frontier models have been trained hard on boundary-setting and respectful language. AI-Specific Communication Quality is the hardest (1.75-3.11 range) models consistently produce verbose, templated, or over-hedged responses even when their clinical reasoning is sound.
Scale and reasoning do not reliably help. GPT-oss-120B and Qwen3-235B-Thinking underperform several smaller, non-reasoning models. Gemma3 12B outranks Gemma3 27B. The benefits of scale and test-time reasoning have been demonstrated primarily in math and coding, and those skills do not transfer cleanly to the interpersonal, slow-paced work of therapy. One of our annotators put it bluntly:
"The AI kept patients in their comfort zone, prioritizing the removal of any pressure, emphasizing micro-interventions, avoiding deeper emotional or behavioral work, and using language that discouraged engaging with discomfort. This reinforced avoidance, signaled fragility and 'unsafe to feel uncomfortable,' and created conditions unlikely to produce meaningful therapeutic change."
That failure mode is the flip side of helpfulness training. "User is always right" is the wrong objective for therapy.
How performance changes under stress
We ran three ablations to probe robustness:
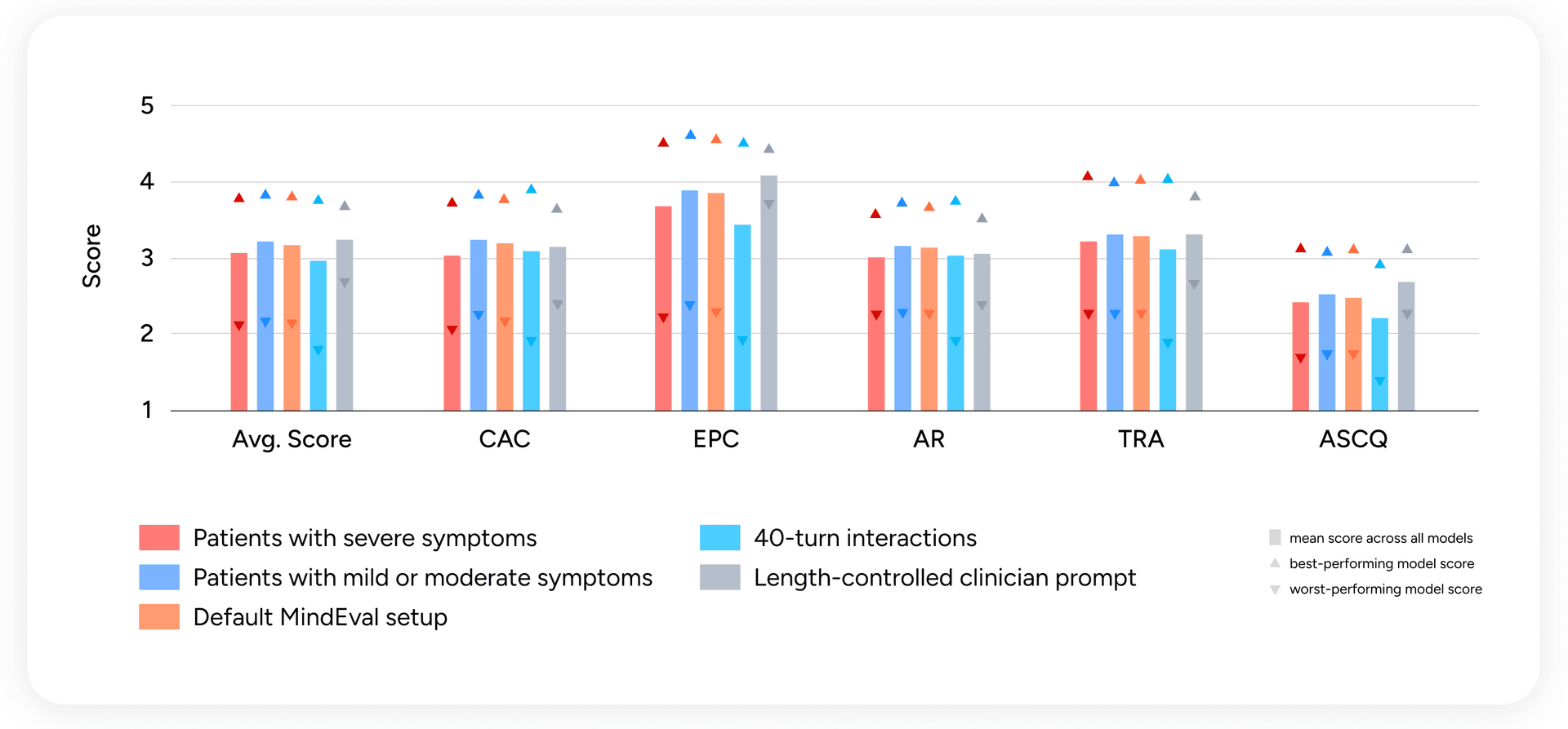
Figure 4 — Per-criterion scores across patient severity, interaction length, and prompt length control. Bars are means; upward triangles are best-model scores; downward triangles are worst-model scores.
Severe symptoms degrade performance across the board. When we split interactions by patient symptom severity, scores drop by up to 5% on interactions with severely depressed or anxious patients. This is exactly where reliability matters most, and exactly where models are weakest. An annotator on one such transcript:
"The AI gave this patient with low energy and severe depressive symptoms 4 options [...] this can create analysis paralysis in anyone, but especially in someone with severe depression. This seems to be out of tune with what the patient would really be capable of handling."
Longer interactions degrade performance. Extending from 20 to 40 turns produces a clear drop across every criterion. This is directly relevant: real therapeutic engagement unfolds over dozens or hundreds of turns, and models need to stay consistent across that horizon.
Length bias in the judge is not linear. We worried that the judge might reward verbose clinician turns, a known bias of LLM-as-judge. When we constrained the clinician to ≤4 sentences per turn, mean scores increased, minimum scores went up across the board, and only the best-case ceiling dropped. In other words, the judge is not systematically favoring length; if anything, forced concision helps most models. We also release a judge-prompt variant that explicitly penalizes turn length for users who want to be extra cautious about verbosity.
Robustness to judge and patient swaps
We tested swapping the patient LLM (using GPT-5 Chat instead of Claude 4.5 Haiku) and the judge LLM (GPT-5 and Gemini-2.5-Pro instead of Claude 4.5 Sonnet). System-level pairwise ranking agreement with the default leaderboard stays above 0.85 in both cases. Self-preference bias is visible here too, consistent with the patterns we characterized in our self-preference work: GPT-5 as judge ranks GPT-5 as clinician higher than other judges do. The effect doesn't dominate the ranking, but it's measurable, and it reinforces the recommendation from the previous section. MindEval users benchmarking a model from a given family should judge with a model from a different family, and ensembling judges across families is the more robust default when compute allows.
Limitations
MindEval is not a finished artifact. Working with our psychologist team, we identified several limitations worth stating explicitly.
The persona-style-transparency trade-off. LLMs simulating patients tend to either caricature the profile or collapse into a handful of generic modes. The MindEval prompt threads this needle better than alternatives, but simulated patients still share more openly and accept suggestions more readily than real patients typically would. The variability in Cluster A of Figure 2, where humans disagree, deflect, and disengage, is still underrepresented in LLM-generated turns.
Safety-bounded scenario coverage. We deliberately exclude interactions involving imminent self-harm, threats to others, and mandated reporting situations. An early version of the rubric included a Safety and Crisis Management axis, but we found current models either behaved uniformly safely or refused to engage at all (sometimes due to API-level restrictions), producing no meaningful variation. Evaluating unsafe-scenario handling is possible within the MindEval framework given better patient simulation and judge design — it's a direction for follow-up work.
Absence of longitudinal dynamics. Real therapy unfolds across weeks and months. Alliance formation, rupture and repair, evolving case conceptualization, and motivational change happen across extended engagement. MindEval's 20-40-turn sessions capture process-level therapeutic behaviors but not longitudinal dynamics. Multi-session evaluations are the natural next step.
Intrinsic vs. extrinsic evaluation. Our meta-evaluation shows strong correlation with human expert judgments, but clinical-competence rubrics are ultimately a proxy for the only thing that truly matters: whether interacting with an AI system leads to better patient outcomes. Measuring outcomes is hard for human therapists too, and it's an open problem we don't solve here.
Key learnings
Three things from the build process that we think generalize beyond mental health:
- Expert co-design matters more than expert review. The patient backstories, the prompt constraints, the rubric anchors, and the annotation guidelines were iterated collaboratively with psychologists from day one. When clinical input shows up only at the end as a review step, it becomes corrective instead of foundational, and it's too late to change the framework's shape.
- Prompt design beats prompt length. Adding more instructions to patient simulation prompts past a certain point collapsed behavior into uniform failure modes. The single biggest realism gain came from adding the backstory, a structured grounding document, not from adding more rules.
- Meta-evaluation is the benchmark. Leaderboards without demonstrated agreement with human experts are aesthetic exercises. Most of the engineering effort in this project went into the meta-evaluation, and we would recommend the same split to anyone building a domain-specific benchmark.
What's next
Two directions we're actively working on.
First, extending MindEval to speech. Therapists extract an enormous amount of information from vocal cues — hesitations, affect, pacing — and a text-only benchmark misses all of it. This connects directly to our real-time voice work on Phoenix.
Second, simulating high-risk patient scenarios. This is the hardest and most consequential ground for AI in mental health, and the domain where the gap between current models and clinical reliability is widest.
MindEval is designed to stay useful as models improve. Patient simulation, clinician behavior, and evaluation are all model-agnostic components, and every piece gets sharper as the underlying LLMs do. The scores will go up. The question is whether the systems that produce them will be ones you would want your friends and family talking to. That's what we're trying to measure.
Open-source release
We are releasing everything needed to reproduce, extend, or build on this work:
- A repository with all code, prompts, and the attribute-sampling and backstory-generation pipelines.
- The human-generated patient turns used to validate patient realism, so others can benchmark new patient language models.
- The 240 human annotations from our psychologist panel, so others can benchmark new judges.
Read the full paper: MindEval: Benchmarking Language Models on Multi-turn Mental Health Support.
Acknowledgements
This work was led by the Sword Health AI Research Team in collaboration with our Clinical Team, whose input shaped every stage of the framework — from patient profile design to evaluation rubrics to the annotation campaigns that validated the judge. MindEval would not exist without them.